Activity
Mon
Wed
Fri
Sun
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
What is this?
Less
More
Memberships
AEO - Get Recommended by AI
1.6k members • Free
11 contributions to AEO - Get Recommended by AI

18d •
Quick AEO Update: WebMCP Insights
:::::First, a quick personal note—:::: Sorry for being MIA for a while, still in recovery mode, turns out human biology hasn’t quite mastered the "force restart" feature we are so used to in our tech stacks 🤒. You guys know that I like to show up prepared to overdeliver so thanks for your patience, ✌. However, even from the sidelines, the research into the future of AI never stops, and is going faster than ever! As previously announced: We are officially entering The Year of the Agents. - OpenAI is launching their in-platform agentic ecommerce protocol the ACP. - Google is launching their in-ecosystem agentic ecommerce protocol the UCP. - More people are coding and creating apps than ever in agentic frameworks. ------------------------ "Claude Code Usage Patterns Coding remains dominant (36% of tasks), but 2026 shows diversification into education (12.4%) and science (7.2%), with directive automation rising from 27% to 39% of interactions. Token efficiency improved in sample data, with January 2026 sessions using 69% fewer tokens per message than December 2025 despite 181% more messages" Attached: Google Trends: Claude Code ------------------------- We’re moving past simple chatbots, way past that. Applications like Claude Code, Opencode (currently testing this one) and Open Claw are now actively browsing the web to execute tasks. But until now, they’ve hit a bottleneck: they’ve had to "look" at screenshots to navigate, which is slow and expensive. ⭐The Breakthrough: WebMCP I’ve been diving into a brilliant new Google/Microsoft proposal called WebMCP. This is a game-changer for how businesses will be discovered and utilized in an AI-first world. WebMCP allows your website to expose specific tools (via JavaScript or HTML) that AI agents can discover and use automatically. No clunky installations; just seamless interaction. Why This Matters for you? We are witnessing a fundamental shift in digital strategy: We are moving from "designing for human clicks" to "designing for AI actions." Imagine a customer telling their AI assistant, "Go to [Your Site] and order my usual." With WebMCP, the agent doesn't need to scroll or click.

2 likes • 18d
This is great! I believe the WebMCP protocol will evolve over the next few months before it becomes an actual standard. I still built an agent to the current standard that automatically analyzes the available tools on a website and then builds the webmcp interface for those tools. I work in the automotive space and it seems the average dealer has 10 different tools. On the agents themselves, I've been working a lot with openclaw but I still have concerns about security. Claude Cowork is getting there fast and just this week google launched googleworkspace/cli on github that has native connection for agents to google drive, gmail, calendar and every workspace api plus over 40 agent skills already included. Things are moving so quick it's hard to keep up!
Feb 17 •
Goolge WebMCP
I haven't seen anyone talking about this release last week https://developer.chrome.com/blog/webmcp-epp. Any thoughts?
1 like • 21d
@Julian Lopez I'm a bit concerned about the cloudflare md development and how it will impact my own project. Do you see this becoming the 'canonical truth' for agents crawling websites?

Dec '25 •
First sale!
Found Perry secret agency plan - read it on the plane home from a podcast yesterday - sold my first $1000 AEO audit today!
2 likes • Feb 3
That's fantastic! I'm currently negotiating with 3 major OEM's to provide quarterly audits of all their stores. Not what I started off thinking I was going to do, but.....
Jan 20 •
Is ChatGPT Winning on... Search? 🔍
ChatGPT has surpassed major social media and video platforms like YouTube, TikTok, Instagram, and Facebook in global search interest, achieving this milestone in under two and a half years since its launch. According to data from Ahrefs, ChatGPT's monthly search volume overtook YouTube in April 2025 and has since outpaced all other platforms between September 2024 and April 2025. While search volume isn't a perfect measure of usage, it reflects sustained user intent and habit formation. The data also shows that Google still leads in search interest, but the gap has narrowed significantly since early 2023, with projections suggesting ChatGPT could match or even surpass Google’s search volume by 2028–2029 if current trends continue. Source: https://ahrefs.com/blog/chatgpt-vs-other-platforms
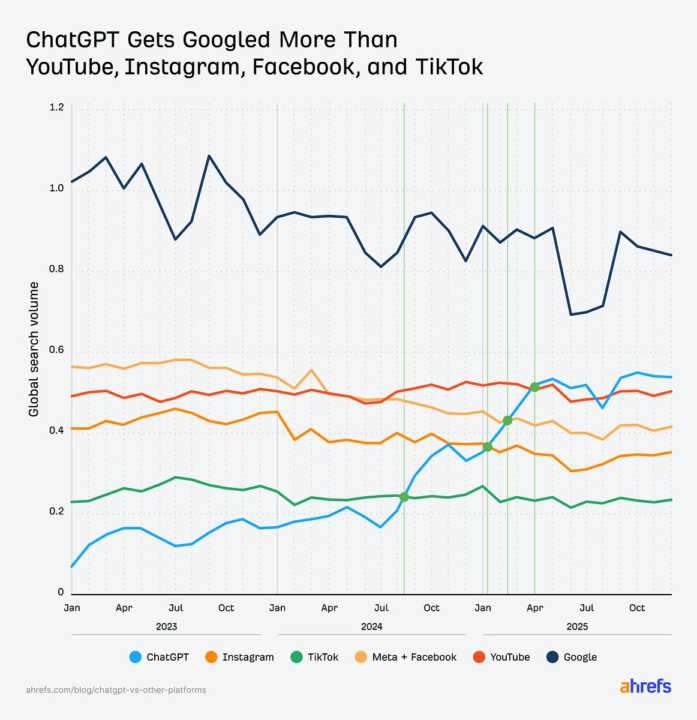
1 like • Jan 20
This is such an important post.

Jan 13 •
Steal my new Entity Graph Tracker
1. Question: What do you use to track your entities, @IDs, relationships, etc.? I´m starting with this multi-tab sheet for a major SEO/AEO client for tracking their knowledge graph - entities, @IDs, and relationships, etc., to be maintained collaboratively with my developers. https://docs.google.com/spreadsheets/d/1ftyCPFrGYpH7fgQ7WKXEJZkNxK1da7rROXKiJXqMYPQ/edit?usp=sharing I´m considering moving it to Fusebase as a searchable database because this client´s site is very large and they are already using Fusebase. Any other platform recommendations @Julian Lopez ? Feel free to test it, poke holes in it, improve upon it, or just use as is, of course. Cheers! Heather P.S. For those who are new to schema and thinking "What is an entity??" I´ll put a quick breakdown of what we’re tracking and why in the comments, and of course to REALLY understand and use this, do READ Kasum & Julian´s AEO Book, do the course, and join the calls!
1 like • Jan 20
We’re tackling this by treating entity tracking less like a doc and more like infrastructure. We still start with a collaborative table for modeling and alignment because it’s the fastest way to get SEOs and devs on the same page. But for us that table is just a staging layer, not the source of truth. A few things we’re doing differently as it scales: - Canonical @ids are created once and never edited. If something changes meaningfully, we version or deprecate it instead of overwriting. - Relationships are explicit and directional. We store why two entities are related, not just that they are. - The actual system of record lives in a structured store where IDs, references, and lifecycle states are enforced, not in the sheet itself. The big failure mode we’ve seen is identity drift once multiple people can casually edit entities. Searchability matters, but referential integrity matters way more. We’re also measuring this in a live pilot right now. Instead of just “did we implement schema,” we track whether those entity relationships actually show up consistently in AI answers over time. Fixed query sets, controlled changes, and then watching whether dealer–vehicle–location relationships stabilize or drift. (we are doing this in automotive) So the sheet helps us plan and collaborate, but measurement is what tells us whether the graph is actually working in the wild. Curious how others are handling entity versioning and deprecation once things evolve. That’s been the hardest part for us so far.
1-10 of 11

@christopher-whitehead-1393
Repeat founder (ex-automotive IPO) focused on Answer Engine Optimization.Here to pressure-test ideas and share evidence-based AEO results.
Active 5d ago
Joined Jan 1, 2026
Powered by