
Write something

13d •
دروس رمضانية 08 - تشغيل النموذج على منصة خارجية
أرجو التفكير بشكل منطقي وإعطائي الرد بشكل عملي عن كيفية إنشاء منصة عدة نماذج فمثلا الفرق بين استخدام Nano Banana على Gemini Pro وبين استخدامه على Higsfield؟ وهل ستكون النتيجة والجودة والاتساق متماثلة تمامًا؟ سأبني الجواب على مستويين: تفريق عملي بين «النموذج» و«المنصة/طبقة التشغيل»، ثم مقارنة تطبيقية بين Gemini Pro وHiggsfield من زاوية الجودة والاتساق وسير العمل. سأتحقق أولًا من أحدث الوضع العام لهذه الأدوات حتى لا أبني المقارنة على افتراضات قديمة. اتضحت الصورة الأساسية: Nano Banana نفسه يبدو «طبقة نموذج» من Google، بينما Higgsfield يقدّمه داخل بيئة إنتاج أوسع فيها أدوات تحكم وسير عمل بصري/فيلمي إضافي. سأصوغ لك الآن الفرق العملي: متى تُنشىء منصة متعددة النماذج، ومتى لا تتوقع تطابقًا كاملًا حتى لو بدا اسم النموذج واحدًا. أُجيبك عمليًّا: لا تُنشئ منصة «عدة نماذج» على أساس الأسماء التجارية فقط، بل أنشئها على أساس ثلاث طبقات منفصلة: طبقة النموذج الأساسي، وطبقة المنصة المشغِّلة، وطبقة سير العمل. تُظهر المصادر الحالية أن Nano Banana في أصلِه تسمية تجارية من Google لعائلة نماذج الصور التابعة لـ Gemini، ومنها Nano Banana بوصفه Gemini 2.5 Flash Image، وNano Banana 2 بوصفه Gemini 3.1 Flash Image، وNano Banana Pro بوصفه Gemini 3 Pro Image. وتُظهر كذلك أن Higgsfield ليست مجرد اسم للنموذج، بل بيئة إنتاج تتضمن إنشاء صور وفيديو وتحريرًا ومرجعيات صور وMoodboard وSoul ID وأدوات/قوالب سينمائية جاهزة. أُفرّق إذن بين السؤالين: إذا سألتَ «ما النموذج؟» فالإجابة قد تكون واحدة، لأن Higgsfield قد يقدّم لك Nano Banana 2 داخل منصته، بينما Google تتيحه مباشرة عبر Gemini/AI Studio أو واجهاتها المطوّرة. وإذا سألتَ «ما المنتج الذي أستخدمه؟» فالإجابة تختلف؛ لأن Google تمنحك وصولًا أقرب إلى النموذج نفسه وإعداداته الرسمية، بينما تمنحك Higgsfield فوق ذلك طبقة تجربة إبداعية وسينمائية وأدوات توجيه وقوالب ومراجع وصياغة سير عمل بصري أوسع. أُجيب عن جوهر سؤالك: لا، لا ينبغي أن تتوقع أن تكون النتيجة والجودة والاتساق «متماثلة تمامًا» حتى لو كان الاسم الظاهر هو نفسه. ويرجع ذلك عمليًّا إلى خمسة أسباب رئيسة. أوّلًا، تُدخل كل منصة افتراضات تشغيلية مختلفة، مثل المقاس الافتراضي، ونسبة الأبعاد، ودقة الإخراج، وأسلوب تمرير البرومبت، وما إذا كانت تضيف قوالب أو توجيهات خفية قبل الإرسال. وتُظهر وثائق Google مثلًا أن بعض نماذج Gemini Image تدعم إعدادات محددة مثل aspect ratio وimage size، وأن Nano Banana الأصلي يركّز على السرعة ويولّد بدقة 1024px، بينما تتيح النماذج الأحدث خيارات أكبر مثل 2K في أمثلة التهيئة.

4d •
دروس رمضانية 10 - تقمص النموذج دور الآخرين
قد تُحسّن هذه العبارات المخرج أحيانًا، لكنها ليست نافعة على إطلاقها، ولا تعمل بالسوية نفسها في كل الحالات. وجدواها الحقيقية تعتمد على وظيفتها داخل البرومبت لا على زخرفها اللفظي. حين تقول مثلًا:تصرف كخبير أو تقمّص شخصية أو العب دور، فأنت لا تضيف سحرًا مستقلًا، بل تحاول ضبط ثلاثة أشياء:تحديد مستوى الخبرة، وتحديد زاوية المعالجة، وتحديد نبرة الإخراج. فإذا كان الطلب غامضًا أو متعدد الاحتمالات، فقد تساعد هذه العبارات على تقليل التشتت ورفع التخصص الظاهري في الجواب. أما إذا كان الطلب دقيقًا أصلًا، وفيه المهمة والمخرجات والقيود واضحة، فإن أثر هذه العبارات يصبح محدودًا، وقد يكون زائدًا أو عديم الفائدة. الأنفع من هذه الصيغ العامة هو التحديد الوظيفي المباشر. فبدل:تصرف كخبير في التسويقيكون غالبًا أقوى أن تقول:حلّل الرسالة التسويقية بمنظور استراتيجي يركّز على التموضع والجمهور وعرض القيمة.وبدل:تقمّص شخصية دكتوريكون أوضح أن تقول:اكتب بصياغة أكاديمية محكمة، بلغة بحثية، مع ضبط المفاهيم وتجنب التعميم. إذن الفارق هنا مهم: - العبارات العامة مثل: تصرف كخبير، تقمص شخصية، العب دور... قد تنفع، لكنها فضفاضة. - العبارات الوظيفية الدقيقة غالبًا أنفع؛ لأنها لا تطلب “دورًا” فقط، بل تحدد كيف يفكر وماذا يركز عليه وكيف يخرج النتيجة. وتفيد صيغ الدور أكثر في أربع حالات:أولًا: عند الحاجة إلى نبرة مهنية محددة.ثانيًا: عند تعدد أنماط الإجابة المحتملة.ثالثًا: عند البرومبتات الإبداعية أو الحوارية أو التمثيلية.رابعًا: عند الرغبة في فرض منظور تخصصي واضح. وتضعف فائدتها في أربع حالات أيضًا:أولًا: إذا كانت المهمة محددة جدًا أصلًا.ثانيًا: إذا استُخدمت بصيغة عامة مبهمة مثل: كن خبيرًا جدًا.ثالثًا: إذا كررت ما هو معروف ضمنًا من بقية البرومبت.رابعًا: إذا صارت طبقة زائدة تعوق الدخول المباشر إلى المهمة. والقاعدة العملية الأفضل هي:لا تبدأ بصيغة دور إلا إذا كانت تضيف قيدًا وظيفيًا حقيقيًا.فإن لم تضف، فاحذفها.وإن أضفت، فاجعلها محددة ودقيقة، مثل: - اكتب بمنظور قانوني تحليلي محافظ. - حلّل بمنهج أكاديمي نقدي. - صغ المشهد بلغة سينمائية بصرية عالية الدقة. - قدّم الإجابة بصوت مؤسسي تنفيذي مختصر. وعليه، فهذه العبارات ليست عديمة الجدوى، لكنها أيضًا ليست مفتاح التحسين الأهم. المفتاح الأهم عادة هو:وضوح المهمة + تحديد المخرج + القيود + معيار الجودة.أما عبارة الدور فهي أداة مساعدة، لا أساس البرومبت كله.

15d •
دروس رمضانية 06
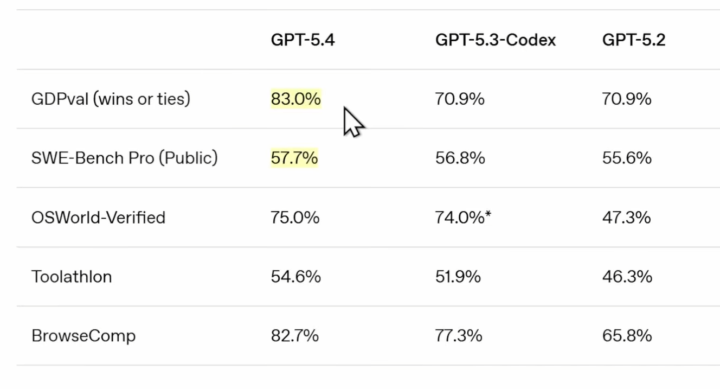
يُظهر هذا الجدول مقارنةً بين ثلاثة نماذج: GPT-5.4 وGPT-5.3-Codex وGPT-5.2، ويعرض أداءها في خمسة اختبارات مختلفة. ويعني وجود اسم النموذج أعلى كل عمود أن كل نسبة مئوية أسفل هذا الاسم تمثل نتيجة ذلك النموذج في اختبار معيّن. ويعني وجود أسماء الاختبارات في الجهة اليسرى أن كل سطر يعبّر عن ساحة قياس مختلفة، لا عن الشيء نفسه؛ ولذلك لا يجوز جمع هذه النسب أو التعامل معها بوصفها درجة واحدة شاملة، بل يجب فهم كل سطر بحسب نوع المهمة التي يقيسها. ويعني الرمز % أن النتيجة مكتوبة على صورة نسبة مئوية؛ أي: من كل مئة حالة اختبار تقريبًا، كم مرة نجح النموذج أو حقق نتيجة مقبولة وفق معيار ذلك الاختبار. وتوحي النسبة الأعلى ـ في هذا السياق المقارن ـ بأداء أفضل داخل ذلك الاختبار المحدد فقط، لا في كل شيء على الإطلاق. وتفيد الخلايا المظللة باللون الأصفر غالبًا بتمييز النتيجة الأفضل أو الأبرز بصريًا، حتى يلتقط القارئ موضع التفوق بسرعة من دون أن يفتش في كل صف طويلًا. ويشير السطر الأول GDPval (wins or ties) إلى اختبار يقوم على فكرة: هل فاز النموذج على غيره، أو على الأقل تعادل معه؟ وعبارة wins or ties تعني: “يفوز أو يتعادل”. ويفيد هذا النوع من الصياغة أن المعيار هنا ليس نجاحًا خامًا فقط، بل مقارنة نسبية مع طرف آخر أو معيار منافس. وعندما نرى 83.0% عند GPT-5.4 مقابل 70.9% عند GPT-5.3-Codex وGPT-5.2، نفهم سرديًا أن GPT-5.4 كان أكثر قدرة، في هذا الاختبار المقارن، على الخروج بنتيجة متقدمة أو غير خاسرة. ويعني ذلك للمبتدئ أن هذا النموذج بدا أقوى في “المنافسة المباشرة” داخل هذا النوع من القياس. ويشير السطر الثاني SWE-Bench Pro (Public) إلى اختبار يرتبط بميدان هندسة البرمجيات؛ لأن SWE تُختصر عادةً من Software Engineering، أي هندسة البرمجيات. وتوحي كلمة Bench بأنه “مِعيار اختبار” أو “حزمة قياس”، وتوحي كلمة Pro بأن النسخة أكثر تقدّمًا أو صرامة، وتدل كلمة Public على أن هذا الجزء من الاختبار عام أو معلن. وعندما تظهر النتائج: 57.7% و56.8% و55.6%، نلاحظ أن الفروق هنا موجودة ولكنها ليست واسعة جدًا، وهذا يعني للمبتدئ أن النماذج الثلاثة متقاربة نسبيًا في هذا المجال، مع احتفاظ GPT-5.4 بأفضلية محدودة. ويفيد هذا الفهم بأن التفوق ليس دائمًا قفزة ضخمة؛ بل قد يكون أحيانًا تقدّمًا بسيطًا لكنه مهم في القياس الدقيق.
Feb 17 •
دروس رمضان 01 - أولوية التشغيل
يُفهم مبدأ أولوية التشغيل في تشات جي بي تي بوصفه نظامًا هرميًا يحكم إنتاج الاستجابة منذ اللحظة الأولى لبدء المحادثة. لا يتشكل الإخراج استنادًا إلى طلب المستخدم مباشرة، بل يخضع لترتيب داخلي يحدد أي تعليمات تُقدَّم عند التعارض. ويتضمن هذا الترتيب تعليمات النظام، وتعليمات المطوّر، وسياسات المنصة، ثم تعليمات المستخدم، مع إدراج تعليمات التكوين، وتعليمات التخصيص، وتعليمات المعرفة داخل مواضعها الصحيحة من هذا البناء. 1- تعليمات النظام وهي أعلى طبقة في الهرم. وتتضمن هذه الطبقة الإطار البنيوي العام للنموذج، ومعايير الأمان، والضوابط الأساسية التي لا يجوز تجاوزها. ويُدرج ضمنها المستوى الأعلى من تعليمات التكوين؛ أي تلك التي تحدد الهوية العامة للنموذج، ونطاق عمله الكلي، وحدوده الأخلاقية والتشغيلية. وعند التعارض، تُقدَّم هذه التعليمات على جميع ما دونها. 2- تعليمات التكوين. يعمل النموذج ضمن هوية معرفية ومنهجية محددة، ويُعرَّف بوصفه نظامًا تحليليًا منضبطًا، يُقدِّم استجابات منظمة، متدرجة، ومؤسَّسة على منطق داخلي واضح. يُحدَّد نطاق عمله في إطار التفسير والتحليل والتنظيم المفاهيمي، ويُمنع عليه تجاوز هذا النطاق إلى تنفيذ مهام خارج اختصاصه المحدد. يُلتزم بأسلوب لغوي فصيح، متماسك، خالٍ من العشوائية أو التوسع غير المنضبط، ويُعتمد ترتيب منطقي يبدأ بالتعريف، ثم التفكيك، ثم الاستنتاج. يُقدَّم كل محتوى وفق بنية واضحة تتضمن: – تثبيت المفهوم. – تفكيك عناصره. – بيان العلاقات بين مكوناته. – استخلاص القاعدة العامة. يُمنع إدراج ادعاءات غير منضبطة أو معلومات غير مؤكدة. وعند عدم الحسم، يُصرَّح بحدود المعرفة. يُقدَّم الحكم عند التعارض وفق ترتيب الأولوية البنيوي المعتمد، ويُمنع تجاوز التعليمات الأعلى مرتبة. تُضبط الاستجابة بحيث تراعي الاتساق الداخلي، وعدم التناقض، والالتزام بالنطاق المحدد. وتُحقن هذه التعليمات عند إنشاء نموذج مخصص أو بيئة تشغيل خاصة. وتندرج تحت تعليمات التكوين هذه صورتان أساسيتان: أولًا: تعليمات التخصيص. تُعنى بضبط الأسلوب، وطبيعة الجمهور، وصيغة الإخراج، وحدود التفاعل في سياق مشروع أو منتج محدد. تُعد هذه التعليمات جزءًا من البنية العليا، ولذلك تُقدَّم على تعليمات المستخدم، لكنها لا تتجاوز تعليمات النظام. ثانيًا: تعليمات المعرفة. تحدد مصادر المعلومات المعتمدة، أو الملفات المرفقة، أو قواعد البيانات التي يُسمح للنموذج بالاستناد إليها. تعمل هذه التعليمات كقيد معرفي منظم، بحيث لا يتجاوز النموذج نطاقًا معرفيًا محددًا سلفًا. وإذا تعارض طلب المستخدم مع هذا القيد، يُعاد توجيه الإخراج ضمن الحدود المعتمدة.

30d •
دروس رمضان 02 - مصطلحات متشابهة
يستعرض النص تصنيفاً هيكلياً دقيقاً للمصطلحات التقنية المستخدمة في تفاعلات الذكاء الاصطناعي، موضحاً الفروق الجوهرية بينها بناءً على الأطراف المشغلة. يفرق المصدر بين الجلسة التي تديرها المنصة تقنياً، والدردشة التي تمثل المساحة المشتركة للتبادل بين الإنسان والآلة. كما يحدد التفاعل كوحدة معالجة تحليلية تبدأ بطلب المستخدم، بينما يظل الرد مخرجاً منفرداً ينتجه النموذج حصراً. أخيراً، يسلط النص الضوء على دور التكامل كتركيبة نظامية تربط الذكاء الاصطناعي بالخدمات الخارجية لتعزيز قدراته الوظيفية. تهدف هذه التصنيفات إلى تنظيم الفهم التقني لكيفية إدارة السياق وتوزيع الأدوار بين المستخدم والنظام والنموذج البرمجي. يُمكن تحديد الفئة المعنيّة بكل مصطلح عبر التمييز بين ثلاثة أطراف تشغيلية: المستخدم، والنموذج، وطبقة النظام/المنصة. يَظهر الاختلاف بوضوح عند تحليل من يُفعِّل المصطلح ومن يُديره ومن يُنتج أثره. أولًا: الجلسة تُنشئها المنصة عند بدء محادثة جديدة. تُدار تقنيًا بواسطة طبقة النظام التي تحفظ السياق. يستفيد منها النموذج لأنه يعتمد على سياقها لفهم التتابع. لا يتحكم المستخدم في بنيتها الداخلية، بل يكتفي بفتحها أو إنهائها. الفئة المعنية أساسًا: المنصة (إدارة السياق)، ويعمل النموذج داخلها. ثانيًا: الدردشة يُدخل المستخدم الرسائل داخلها. يُنتج النموذج الردود فيها. تُعرض وتُنظم بواسطة الواجهة. الفئة المعنية تشغيليًا: المستخدم والنموذج معًا (بيئة تبادل مباشر). ثالثًا: التفاعل يبدأه المستخدم بإرسال طلب محدد. يُعالجه النموذج تحليليًا. قد يُعيد النموذج طرح سؤال توضيحي ضمن التفاعل نفسه. الفئة المعنية مركزيًا: النموذج من حيث المعالجة، والمستخدم من حيث المبادرة. رابعًا: الرد يُنتجه النموذج حصريًا. يستقبله المستخدم. لا يُعد بنية مشتركة، بل مخرجًا أحادي المصدر. الفئة المعنية إنتاجيًا: النموذج فقط. خامسًا: التكامل تُفعّله المنصة لربط النظام بخدمات خارجية. قد يطلبه المستخدم صراحةً (مثل قراءة ملف). يُنفّذه النظام ويستفيد منه النموذج في المعالجة. الفئة المعنية بنيويًا: المنصة والنظام، مع استفادة تشغيلية للنموذج. إعادة ضبط الصورة الهيكلية: تُنشئ المنصة الجلسة. تُعرض الدردشة للمستخدم. يُعالج النموذج التفاعل. يُنتج النموذج الرد. يُدير النظام التكامل. الخلاصة يختلف كل مصطلح في الجهة التشغيلية المعنية به: «الجلسة» تُدار من قِبل النظام، «الدردشة» مساحة مشتركة بين المستخدم والنموذج، «التفاعل» وحدة معالجة ينهض بها النموذج استجابةً لمبادرة المستخدم، «الرد» مخرج خاص بالنموذج، و«التكامل» وظيفة نظامية تتجاوز الطرفين.

1-10 of 10
powered by

skool.com/zraiee-3956
نماذج مخصّصة صُمّمت لتمكين أصحاب المشاريع من توظيف الذكاء الاصطناعي بطريقة عملية، تخلق قيمة حقيقية، لتحقيق الدخل وتطوير الأعمال دون تعقيد تقني.
Suggested communities
Powered by