
Pinned

Dec '25 •
Mastering Local AI: High-End Automatisierung mit 100% Datenschutz
Willkommen im Maschinenraum der lokalen KI-Automatisierung! 🚀🔒 Du willst die Power modernster KI nutzen, aber deine sensiblen Daten nicht an OpenAI & Co. senden? Du suchst nach Wegen, komplexe Business-Prozesse (wie Buchhaltung oder Videoanalyse) vollautomatisch und DSGVO-konform auf deiner eigenen Hardware abzubilden? Dann bist du hier richtig. "Mastering Local AI" ist die Community für Unternehmer, Entwickler und Automatisierungs-Enthusiasten, die die Kontrolle behalten wollen. Was dich hier erwartet: - Deep Dives: Wir gehen tief in die Technik. Keine Oberflächen-Theorie, sondern echte Umsetzung. - Der Tech-Stack: Alles rund um n8n (Self-Hosted), Docker, lokale LLMs (Llama 3, Mistral), Whisper, Paperless-ngx und mehr. - Real-World Use Cases: Wir bauen Systeme, die echte Probleme lösen – von der automatischen Vorkontierung bis zur Medien-Analyse. - Hardware & Setup: Wie rüstet man den eigenen Server/Mac auf, damit die KI rennt? Hier bauen wir die Automatisierung der Zukunft – unabhängig, leistungsstark und lokal. Lass uns die Black Box öffnen.
0
0
Pinned
Dec '25 •
Willkommen bei "Mastering Local AI" – Dein Startpunkt! 🚀
Hallo und herzlich willkommen! 👋 Schön, dass du dabei bist. Ich bin Michael Gross und ich habe diese Community gegründet, weil ich glaube, dass die Zukunft der Automatisierung lokal ist. Wir alle lieben die Möglichkeiten von KI. Aber wir wissen auch: Echte Business-Daten gehören nicht immer in die Cloud. Die Lösung liegt darin, die Intelligenz (LLMs, Transkription, OCR) zu uns zu holen – auf unsere eigenen Server und Rechner. Genau das werden wir hier gemeinsam meistern. Ich werde hier meine Workflows (z.B. meine vollautomatische Buchhaltung mit n8n & Llama 3) teilen, aber ich möchte auch von EUCH lernen. Damit wir uns alle besser kennenlernen, stell dich bitte kurz in den Kommentaren vor: 1. Wer bist du? (Name & was du beruflich machst) 2. Dein Status Quo: Arbeitest du schon mit n8n oder lokalen KIs, oder fängst du gerade erst an? 3. Dein Ziel: Welchen nervigen Prozess würdest du am liebsten sofort lokal automatisieren? Ich mache den Anfang in den Kommentaren. 👇 Auf einen genialen Austausch! Michael
Apr 16 •
Qwen3.6 35B A3B - Faszinierend ist untertrieben, vor allem was Coding angeht
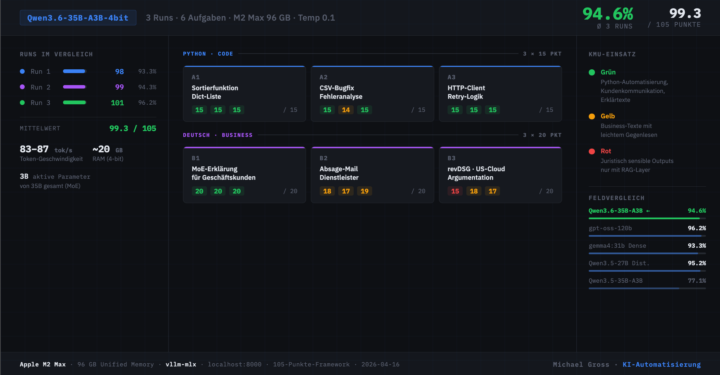
🧪 Qwen3.6-35B-A3B-4bit auf meinem M2 Max (96 GB), drei Runs auf meinem 105-Punkte-Benchmark. Das neue Modell spielt in der Top-Liga, aber mit einer klaren Schwachstelle. ───────────────────────────── 📊 DIE ZAHLEN ───────────────────────────── Drei unabhängige Runs, 6 Aufgaben, Temperatur 0,1. 🟣 Run 1: 98/105 (93,3%) 🟢 Run 2: 99/105 (94,3%) 🔵 Run 3: 101/105 (96,2%) Mittelwert: 99,3/105, also 94,6 %. Damit liegt das Modell gleichauf mit gpt-oss-120b und gemma4:31b Dense, bei nur 3B aktiven Parametern und rund 20 GB RAM. Konstant 83 bis 87 tok/s. ───────────────────────────── ⚡ DIE CODE-QUALITÄT IST BEMERKENSWERT ───────────────────────────── Drei Python-Aufgaben: Sortierfunktion, CSV-Bugfix, HTTP-Client mit Retry-Logik. Über alle drei Runs: 🟣 A1 Sortieren: 15, 15, 15 🟢 A2 CSV-Debugging: 15, 14, 15 🔵 A3 HTTP-Client: 15, 15, 15 Das Interessante ist nicht die Punktzahl, sondern die Stilvarianz. Gleicher Prompt, drei völlig unterschiedliche produktionsreife Lösungen. Beim HTTP-Client: Run 1 zentralisiert mit einem _execute_request-Helper. Run 2 liefert Context Manager plus Retry-After-Header-Parsing. Run 3 trennt sauber in _should_retry und _wait_before_retry. Alle drei brauchbar. Das ist Stilvarianz auf hohem Niveau, nicht Qualitätsvarianz. ───────────────────────────── ⚠️ DIE SCHWACHSTELLE ───────────────────────────── Juristische Texte. In jedem der drei Runs hat das Modell bei revDSG-Argumentation Artikelnummern halluziniert. Run 1: FDPB statt EDÖB, Art. 31 falsch zugeordnet Run 2: "Unterlageverarbeitungsverträge" statt Auftragsverarbeitungsverträge Run 3: Art. 5 und Art. 6 revDSG falsch zitiert Die Konzepte sitzen, FISA 702, EO 12333, Angemessenheit. Aber die Paragraphen-Zuordnung wackelt. Für juristisch sensible Outputs ohne RAG-Layer nicht einsetzbar. ───────────────────────────── 🎯 FAZIT FÜR DEN KMU-EINSATZ ───────────────────────────── Grün: Python-Automatisierung, Kundenkommunikation, Erklärtexte für nicht-technische Stakeholder. Gelb: Business-Texte brauchen Gegenlesen, Sprache schwankt (Genus-Fehler, gelegentlich schiefe Formulierungen).
Apr 24 •
Endlich lokal
Heute war der Tag, an dem es endlich klick gemacht hat. Nicht weil ich eine neue Technologie entdeckt habe. Sondern weil ich zum ersten Mal gespürt habe, wie sich ein vollständig lokales AI-Coding-Setup anfühlt, wenn es wirklich funktioniert. Morgens: .NET-Migration mit lokalem Sprachmodell. Backend, C#, BouncyCastle, iText7, Security CVEs. Das Modell hat gebaut, geprüft, korrigiert. Kein Cloud-API, keine Daten die das Haus verlassen. Mittags: Cline in VSCodium eingerichtet. Temperatur korrigiert, CLAUDE.md hinterlegt, Vue-Frontend analysiert. Das Modell hat den Repo-Kontext gelesen und Fragen gestellt bevor es gehandelt hat. Abends: n8n MCP Server gebaut und in Cline eingebunden. Cline kann jetzt gleichzeitig meinen Code lesen und meine n8n Workflows lesen. Lokales Modell, lokale Automatisierung, lokale Daten. Der Moment wo es klick macht ist nicht spektakulär. Es ist der Moment wo du merkst, dass du dem Tool vertraust. Weil du weißt wo die Daten sind. Weil du den Server-Log siehst. Weil du die Temperatur selbst eingestellt hast. Das ist kein Produkt das ich empfehle. Das ist ein Setup das ich selbst täglich nutze, für echte Kundenprojekte, mit echten Daten, unter DSGVO. Wer das auch aufbauen möchte: es braucht einen guten Nachmittag, einen M2 Mac mit genug RAM, und die Bereitschaft ein paar Build-Fehler zu debuggen. Es lohnt sich. Welchen Teil davon würdet ihr euch genauer anschauen?
1
0
Apr 15 •
Modell Finetuning, was ist das Ergebnis ?
🧠 Du brauchst keinen besseren Prompt. Du brauchst ein Modell, das dein Business versteht. Ich habe das gleiche 7B Modell zweimal gegen die gleiche Aufgabe antreten lassen. Einmal mit einem langen, detaillierten System-Prompt. Einmal feingetuned auf 327 Beispielen. Das Ergebnis war eindeutig. ━━━━━━━━━━━━━━━━━━━━━━ Der Use Case: Kundengespräche einer Gartenbaufirma automatisch analysieren und bewerten. Das Modell muss Budget, Fläche, Material, Untergrund und Eigentümerstatus erkennen, auch wenn der Kunde chaotisch redet. Das Setup: ① Trainingsdaten synthetisch erzeugen → 35B Modell generiert 400 Gespräche (390 fehlerfreie) → Gleiches 35B Modell annotiert die Gespräche im gewünschten JSON-Schema → Ergebnis: 327 saubere Trainingsbeispiele ② Training auf dem 7B Modell → 80/20 Split (Training / Validierung) → 600 Iterationen, Batch-Größe 2 → Bester Checkpoint nach ca. 200 Iterationen (danach beginnt das Auswendiglernen) ━━━━━━━━━━━━━━━━━━━━━━ Die drei Testszenarien, und was mich überrascht hat: Szenario 1, positiv: Das Originalmodell listet den Zeitraum als fehlende Info, obwohl der Kunde "Ende Mai" gesagt hat. Das feingetunte Modell erkennt es korrekt. Szenario 2, negativ: Lead Score 25 vs. 15. Das feingetunte Modell bewertet die Gesprächsqualität realistischer, weil kein Budget erkennbar ist. Szenario 3, Chaos: Der Kunde springt zwischen Rasenmäher, Urlaub und Terrasse. Und dann sagt er, der Hund zerstört immer den Rasen. Das feingetunte Modell erkennt daraus: Untergrund ist Rasenfläche, draußen. Das Originalmodell listet den Untergrund als fehlend. Das Modell hat nicht nur das Schema gelernt. Es hat gelernt, was in diesem Kontext wichtig ist. ━━━━━━━━━━━━━━━━━━━━━━ Wann lohnt sich Feintuning überhaupt? ▸ Immer die gleiche Aufgabe ▸ Fixes Output-Schema (JSON, strukturierte Ausgabe) ▸ Domänenspezifischer Kontext (Fachbegriffe, Branchenlogik) ▸ Beispiele vorhanden oder synthetisch erzeugbar ▸ Kosten und Latenz spielen eine Rolle (kleineres Modell, kürzerer Prompt)
0
0
1-13 of 13
powered by

skool.com/mastering-local-ai-6471
Baue High-End Workflows mit n8n & lokalen LLMs auf eigener Hardware. Maximale KI-Power bei voller Datensouveränität. Join us!
Suggested communities
Powered by