
Pinned

May 3 •
The Folder System Became My Agency
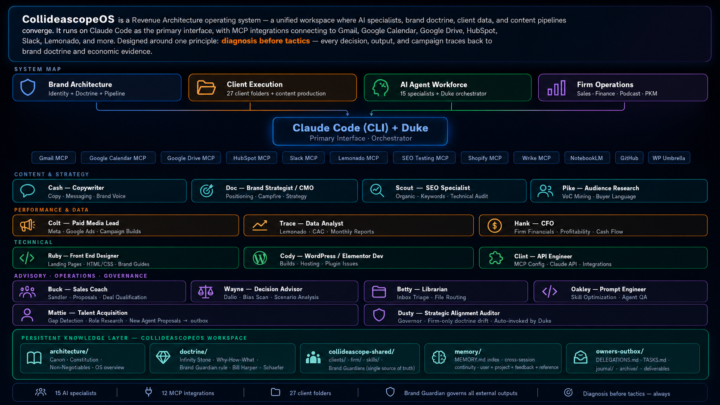
Twenty-four days ago I posted about Jake's folder system video. This is what happened next. Same foundation — markdown files, orchestration prompts, clear roles. I just kept building. Fifteen named specialists. Each one with a soul file, guardrails, and a playbook. Duke orchestrates. Cash writes. Trace pulls the data. Hank runs the financials. Clint handles the MCP integrations. Behind each one is either a human counterpart doing the real work alongside them — or a role I can't afford to hire yet. Katie who's been with me for 18 years, now has her own orchestrator running the same system. Twenty-seven client folders. Twelve live MCP integrations. One shared repo. The folder system isn't replacing my agency. It becoming my agency. Jake gave me the unlock. This is how it's going.
Pinned

Mar 15 •
Welcome to Clief Notes. Here's where to start.
1. Watch the intro video and introduce yourself in the intro post here 2. Start with The Foundation (free course). Concepts, folder architecture, prompting framework. Everything else builds on this. 3. Check in at the bottom of each lesson. Polls, discussion posts, other members working through the same stuff. Use them. 4. When you're ready to build real things, move to Implementation Playbooks (Level 2). When you're ready to build your own tools, Building Your Stack (Level 3). 5. Post your work. Ask questions. Help others when you can. What are you here to build?
Poll
6606 members have voted
Pinned
5d •
🏆 WEEKLY COMP #7: THE OPERATOR 🏆
🎟️ PRIZE: FREE SEAT IN THE LYCEUM 🎟️ Pick your cohort. Technical, Business, or Creator. Your call. ---- 🇬🇧 We're back. Good morning from London. 👋 Thanks for the patience last week. Jake and I needed a few days to breathe before London Tech Week kicked off, and you all responded with nothing but support. We don't take that for granted. Now let's get back to building. ---- 📋 THE CHALLENGE Build a folder-based AI operator that handles ONE operational workflow end-to-end. You pick the workflow. This week's deliverable is one operator folder that someone could drop into a Claude project and use to handle a real business workflow without babysitting. ---- 🎯 PICK YOUR WORKFLOW The workflow is yours. Pick something specific. Pick something you'd actually use. A few sparks to get you thinking: - 🎫 Customer support triage (which tier handles this ticket?) - ✅ Content review and approval - 📨 Lead intake and qualification - 💸 Refund request handler - 🤝 Partnership pitch evaluator - 🎙️ Podcast guest pitch sorter - 💼 Freelance project intake - 📄 Resume screen for one specific role - 📅 Meeting request triage (book, decline, delegate) The more specific, the better. "Customer support" is too broad. "Refund request triage for an ecommerce store doing under 200 orders per month" is right. 📎 If you want a fully written client brief as a reference, the attached PDF walks through one example. Don't build the example. Use it as a template for how to think about scoping your own operator. ---- 🗂️ THE METHODOLOGY If this is your first comp, welcome. Here's what you need to know: This week (and every week) you're learning interpretable context methodology. Folders as architecture. Each file does one job well. Your operator is a folder with five things: - 📄 identity.md (who the operator is and what workflow they own) - 📐 rules.md (the decision logic: criteria, edge cases, escalation rules) - 💬 examples.md (decisions in action, including at least one edge case) - 📚 reference/ (checklists, templates, rubrics) - 📖 README.md (how to use it)

4h •
Kimi K2.7 Code Is out! 30% less reasoning tokens
So the new Kimi K2.7 Code model just dropped. So, when an AI reasons through a problem, it uses tokens, which cost money and add latency. K2.7 cuts that reasoning token usage by 30% - +21.8% on coding tasks, +11% on general programming, and +31.5% on multi-language work across Python, Rust, and Go - Better instruction following on long, complex coding sessions that span many steps - Scores 81.1% on tool-use benchmarks, beating Claude Opus 4.8's 76.4% Has a 256K Context Window. Takes: Images: png, jpeg, webp, gif. Videos: mp4, mpeg, mov, avi, x-flv, mpg, webm, wmv, 3gpp API Pricing: 0.19 USD per 1m tokens if the Cache hit 0.85 USD per 1m tokens if the Cache Misses 4 USD per 1m output tokens. Decent long-horizon coding capabilities. So, where to exactly use this model? I'd say the best way to use it is with an orchestrator and smaller agents. 1 of the frontier, expensive and smart model's (Fable's out of the situation for now because of the recent government complications so Opus 4.8 works). Orchestration, planning and very critical tasks go to the main model whereas everything else goes to Kimi K2.7 Code to build it all out, now again don't just use Kimi K2.7 for everything, use it when you're building a heavy project, but if you're writing content, going through a workflow process or brainstorming, there's better and cheaper models.
1d •
SkillOpt — Has Anyone Looked at This?
A CEO of an MSP that I've been one on one consulting on ICM sent this article to me this morning. Microsoft's SkillOpt automatically upgrades AI agent skills without touching model weights Repo: https://github.com/microsoft/SkillOpt The short version: instead of fine-tuning model weights, it treats your markdown skill files as the trainable parameter. It runs your agent against benchmark tasks, analyzes what went wrong, proposes bounded edits to the skill doc, and only accepts changes if held-out validation strictly improves. The deployed artifact is a single best_skill.md file — no extra model calls at inference. They're reporting +19.1 points on Claude Code benchmarks. That's output quality — the agent getting the right answer more often — not token savings. When I first started building skills in my ICM, they were bloated. Long, unstructured, burning tokens. If you're letting Claude build your skills for you (which is the natural thing to do), you're not necessarily getting an optimized artifact — you're getting whatever Claude thought was thorough at the time. The question SkillOpt is trying to answer: is the skill actually performing, or is it just big? Where I'm less sure it translates: most of the benchmarks are coding tasks, where "correct" is binary. I have three copywriters — Cash, Clyde, and Wradley. Scoring whether a piece of copy is better is a different problem. Harder to define, harder to gate automatically. Is this a layer worth putting on top of nuanced specialist work? Has anyone here dug into it?
1-30 of 1,738

skool.com/cliefnotes
Jake Van Clief, giving you the Cliff notes on the new AI age.
Leaderboard (30-day)
1

🔥
+1603
2

+1442
3
+1127
4

+621
5

+413
Powered by