
Pinned

Mar 15 •
Welcome to Clief Notes. Here's where to start.
1. Watch the intro video and introduce yourself in the intro post here 2. Start with The Foundation (free course). Concepts, folder architecture, prompting framework. Everything else builds on this. 3. Check in at the bottom of each lesson. Polls, discussion posts, other members working through the same stuff. Use them. 4. When you're ready to build real things, move to Implementation Playbooks (Level 2). When you're ready to build your own tools, Building Your Stack (Level 3). 5. Post your work. Ask questions. Help others when you can. What are you here to build?
Poll
6363 members have voted
Pinned
8h •
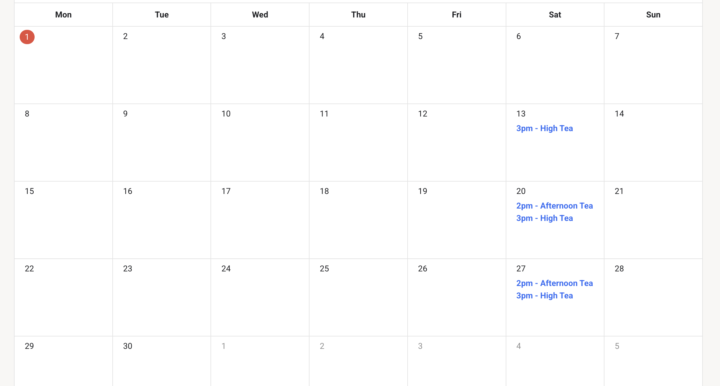
☕ June Tea Schedule
Sat, June 13 3pm: High Tea Sat, June 20 2pm: Afternoon Tea 3pm: High Tea Sat, June 27 2pm: Afternoon Tea 3pm: High Tea Mark your calendars and we'll see you there!
Pinned
3d •
🚨 You've been asking when the Lyceum opens. The waitlist is live. 🚨
The waitlist is up and seats are limited, so this is your nudge to go lock yours in. 👇 New here? Quick context. 👀 The Lyceum is Jake's live cohort program built on ICM, the methodology 35,000 people in this community are already using to get real results with AI. The short version: folders over agents. You learn the layer underneath the tools, the one that keeps working when the next model drops. Full breakdown is on the site. Here's what's inside: 🎯 Three cohorts, Technical, Business, and Creator. Same methodology, built around what you actually do. 🎥 Live sessions with Jake and a full team of instructors. ♾️ Lifetime recordings, written curriculum, and a private cohort Discord. 📜 An Eduba ICM certification you can put on your resume. And a guarantee no course makes: ✅ You leave with a working product, or the team finishes it with you. ⏳ Seats are limited and this community moves fast, so the math is not in your favor if you wait. 💡 Pricing and start dates aren't public yet. The waitlist sees them first, gives feedback on timing, and gets in before the program opens. Everything you want to know is on the page. If you already know this is for you, get on it. 🔥 👉 https://lyceum.eduba.io

2h •
Struggling with switching a project to ICM
I was wondering if anyone has any tips on pivoting an agent you already started working to ICM? Before finding this community I had been trying to build a personal assistant agent. I don’t really want to throw out everything I had built but I’m struggling and feeling overwhelmed trying to convert it over. Has anyone else dealt with similar? Is it easier or maybe better to throw everything out and start from scratch?

2h •
Debugging a Production API Integration with Claude Code and ICM
I debugged a broken production API integration — code I didn't write, in a language I don't speak — without hiring a developer. The ICM is why that was possible. _____________________________________________________________________________________ We run a custom PHP middleware that keeps two platforms in sync. A developer built it. I am not a developer. It had been running degraded for months. Error logs hit 13 million lines in a 4-minute window. Inventory numbers were inflated. Customers added in one system never appeared in the other. A SQL injection vulnerability was sitting quietly in the order dashboard. Nobody touched it because nobody felt qualified to. ____________________________________________________________________________________ Before I did any debugging, I built the workspace. Not "open a chat and paste the error log." Build the folder first so the AI always has the right context for the right task. That's the ICM move. - CLAUDE.md at the root — one file mapping the entire project. What the system does, where every file lives, what each folder is for, what naming conventions to follow. Every session loads this first. - Source files pulled from the server and organized locally into subfolders by function. The server has everything flat. The local folder gives the AI structure to reason about. - A parsed log summary instead of the raw log. 13 million lines uploaded once, converted into a structured breakdown by file, line number, error type, and frequency. Every future session loads the analysis. The noise is already filtered. - A fixes folder and an archive folder. Every fix gets a doc. Every original file gets archived before it's touched. Messy work happens here without polluting the reference layer. - A routing table. A markdown table that answers "I want to do X — go here, load these." Every session goes straight to what's relevant. Once that structure was in place, the workflow was repeatable. Load context, describe the symptom, Claude reads the file and writes the fix, archive the original, deploy via the hosting file manager, update the fix doc. No terminal. No git. No local PHP environment.
1-30 of 1,504

skool.com/cliefnotes
Jake Van Clief, giving you the Cliff notes on the new AI age.
Leaderboard (30-day)
1

+1242
2

+993
3

+824
4

+664
5

+649
Powered by