Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
Jul
What is this?
Less
More
Memberships
AI Workshop Lite
38.6k members • Free
Easy Machine AI
3k members • Free
Creator Academy
9.5k members • Free
Self Publishers Unite!
562 members • Free
Voiceover Masterclass
175 members • $27/month
KDP Publishing
1.3k members • Free
Podcaster Pals
102 members • Free
Creator Party
5.6k members • Free
AI Creator Profits
27.4k members • Free
27 contributions to Clief Notes

23h •
What 1.5 days and about 5 billion AI tokens produced
I just shared the full walkthrough of the Vois website refresh on LinkedIn. I have attached it here too because the process is more useful than the screenshots alone. The headline is big: less than 1.5 days from idea to deployment, with about 5 billion text-agent tokens used along the way. That total excludes image and video generation. Before I posted it, I asked a friend who is a veteran UI/UX designer to review the work. His response: "I hate you. this is good... I hate you for making it" For context, I am the founder of Vois, and this is my own product and codebase. I ran the refresh like a coordinated AI product team. I stayed responsible for the product direction, visual taste, quality bar, and every ship or reject decision. The setup: • GPT-5.6-sol handled the main orchestration. It broke the work into plans, assigned specialist agents, integrated their output, and kept the release moving. • More than 300 specialist sub-agents using GPT-5.6-terra and Grok-4.5 worked in parallel and in sequence across planning, UX, choreography, visual design, asset creation, copy, frontend development, mobile QA, accessibility, browser testing, performance optimisation, and deployment. • Fable-5 acted as an independent advisor. It reviewed alternatives, challenged decisions, and sent weak work back through another pass. • GPT-image-2 generated the images and characters. Grok Imagine generated the video assets. Their generation usage is not included in the roughly 5 billion text-token total. The text-agent token split: Main agent: 13% Sub-agents: 51.3% Advisor agent: 35.7% What shipped: • a complete visual refresh for Vois • a cinematic, scroll-driven homepage • a consistent design system across the site • dedicated desktop and mobile behavior • generated visual and motion assets • accessibility, performance, browser, and deployment fixes The 5 billion total makes the trade visible. I used far more compute and coordination to compress a large design and engineering cycle into less than 1.5 days.
1 like • 12h
Just an FYI, most of the ~5 Billion token were cached tokens.
0 likes • 5h
@Alexandru Bogdan Thanks mate, we do have detailed analytics. No 3JS, good old video and JS trickery
9d •
Roast my two landing pages? (A vs B)
Hey everyone, building in public and could use honest eyes from people who actually get this space. I'm building a white-label AI front desk that agencies resell to local businesses. I made two completely different landing pages and I genuinely can't pick: A) the classic SaaS page: https://a.konvy.ai B) a scroll story, the page plays as you scroll: https://b.konvy.ai Not selling in this post, just asking for critique: which one would make you keep reading, and where exactly do you drop off? Comment A or B plus one sentence why. Brutal beats polite. Mods: if links aren't allowed here, say the word and I'll delete or move them to a comment. UPDATE! Thank you so much for sharing your thoughts and experiences. I collected more than 200+ feedback from various channels and it helped a ton iin making fine grained updates and polishing the experience for variant B. I would like to explain why the variant B actually exists, I have be told by many that I try to go against the grain and challenge the safe, status quo, and force others to think differently. That is what I am trying to do here. White-label is an important feature that lets agencies built their own brand, but it IS in my opinion important to walk and understand the journey first before jumping on the pricing and features. Pricing is extremely competitive, I built the platform from scratch over the last 2 years optimised for latency, pricing and solving real problems for businesses without the fluff. Again thank you so much for help shape this experience, I promise more to come soon.
1 like • 7d
@Mofedul Alam Joy Thank you will do.
1 like • 7d
@Leonard Dauksza Got it, see you there

Apr 26 •
best skills for youtube transcript scraping?
best skills for youtube transcript scraping? go!
6 likes • Apr 28
@Ricky Miskin may I please ask the end goal? thanks @David Vogel the reason I'm asking is that there are quite a few factors, especially when using the skill with, I'm guessing, Claude Code or Codex. Google is actively rejecting requests from OpenAI as well as Anthropic when it comes to YouTube. So if it's part of a workflow, or if you're trying to download transcripts for bulk videos, for any video-related stuff I generally go to Gemini. Gemini is the only model, unfortunately at the moment, that works with videos. I prefer AI Studio (Google AI Studio) for extracting a lot of information and transcribing the videos themselves. The other tool that is incredible, depending on your use case: I generally hook my coding agent to Notebook LM using the Notebook LM scale, and it turns the coding agent into something significantly smarter.

👑
⭐
Apr 25 •
Afternoon Tea Session 2 was crazy fun
Ill be making a bigger write up here shortly on all this but lots of questions, answers and more questions. Play this in the car, on the way home from work or use it like another lesson!

2 likes • Apr 26
Loved the 'more questions' framing of these sessions. One that's been sitting with me - the software you've mentioned building, is it live that we can poke at? Half the fun of these frameworks is seeing where they bend in production.
Apr 24 •
WOW! GPT-5.5 and most awaited Deepseek V4 Flash & Pro dropped today
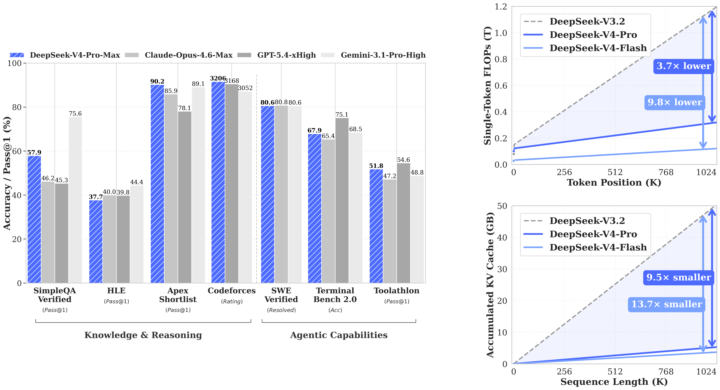
What a Friday. For two years, if you were building anything serious with AI, you were building on Claude. Not because it was a rule — because it was the right call. Anthropic set the bar for coding. They set the bar for writing. They set the quiet default that if you cared about quality, you paid the Opus premium and didn't ask questions. I didn't either. The whole builder community ran on Claude for a reason. This week, that changed. GPT-5.5 shipped yesterday. DeepSeek V4 Pro shipped the same day. Inside twenty-four hours, the ceiling on agentic coding went up — and the open-weight floor came within striking distance of the closed frontier. Real contenders. Not "almost there." Actually here. Three things this changes for anyone building, and none of them are in the headlines yet. Coding: The default setting of "Claude writes the code, Claude runs the agents" breaks this week. GPT-5.5 is measurably better on the kind of long-running multi-step agent work that used to be Claude's moat. DeepSeek V4 Pro is within a fraction on real software engineering, at a price point where "run it myself" is genuinely on the table. Every tool in your stack that quietly assumed Anthropic — your IDE integrations, your review agents, your automation glue — is about to get reconsidered. That's good for you. Less lock-in. More leverage. Marketing and writing: The price-per-draft math just flipped. We've been rationing the good model forever — the flagship handles the brand-safe stuff, volume work gets the cheap model, and we've all quietly accepted that frontier-quality writing at scale isn't possible. That's over. Frontier-quality writing at open-weight pricing means every ad variant, every email rewrite, every landing-page test, every personalization loop runs at the top tier. The whole architecture of "one good draft, fifty cheap copies" starts feeling as dated as shared creative. Everything top-tier. Everything personalized. Everything testable. Agentic work: This is the one I am most excited about, and the most under-talked-about. For two years, "multi-model agent stacks" has been a slide in decks. Nobody actually builds them, because there hasn't been a real second option. GPT-5.5 for the reasoning step. DeepSeek V4 Pro for the long-context research step. Claude for the interpretive writing step. A cheap open model for the high-volume structured step. Not one runtime. A pipeline. Composed by you. Owned by you. That stops being a slide and starts being the default next month.
1 like • Apr 25
@Raquel Nunez spot on
0 likes • Apr 26
@Jarad Nelson I can totally hear you. At my heart, I am a perfectionist as well, and in my past that was the only thing keeping me from moving forward. I have built more than 10 custom harnesses and they all work like a charm, but the amount of time it consumes to maintain and upgrade them—especially working with AI when things change every other day—is jarring. I have learned not to try to reinvent the wheel repeatedly and to stand on the shoulders of giants. Instead of creating my own harnesses, I try to find community-maintained harnesses that are flexible enough for me to build on top of while still being able to ingest upstream updates. Paperclip is a great example that I have grown to like; I have built several custom plugins on top that work in harmony with upstream changes. If you haven't come across it, I suggest you check it out. There are other similar projects, but for now I'm sticking with Paperclip as it provides most of what I want without getting in my way.
1-10 of 27

@praney-behl-3117
Creator, Developer, Entrepreneur, Marketer, Husband & a Dad.
Building Vois.so, konvy.ai, heynyx.app, volant.app and a couple more ;)
Active 51m ago
Joined Mar 10, 2026
Melbourne AUS
Powered by