Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
AI Workshop Lite
30.6k members • Free
Easy Machine AI
2.8k members • Free
Creator Academy
9.3k members • Free
Self Publishers Unite!
548 members • Free
Voiceover Masterclass
161 members • Free
KDP Publishing
1.2k members • Free
Podcaster Pals
100 members • Free
Creator Party
5.6k members • Free
AI Creator Profits
27.1k members • Free
10 contributions to AI Automation Society

💎
⭐
5d •
🚀New Video: Stanford's Method Turns Claude Into a PHD Level Research Team
Stanford's STORM research method runs a topic through five different expert perspectives instead of a single prompt, so the blind spots one angle misses get caught by another. I turned it into a free Claude skill that spins up a practitioner, academic, skeptic, economist, and historian, maps where they disagree, then verifies every source before handing you a clean HTML briefing. I also put it head to head against Claude Code's built-in Deep Research, and walk through exactly how to install it and tweak the lenses for your own work.

0 likes • 4d
Sweeeet...!
Mar 9 •
How I got AI chatbots to recommend my product (before I launched)
Your product is probably invisible to a growing segment of buyers. Not because your SEO is bad. Because they're not using Google. A growing number of people search by asking ChatGPT, Gemini, or Perplexity a question. The AI gives them a ranked list. They research from there. If your product isn't in that answer, you don't exist. I realised this early and did something most founders skip entirely: I built the layer of my website that AI models can actually read and cite. Before writing a single ad or social post, I spent weeks on what I call the "AI-readable layer." Here's what that looked like: 1. llms.txt files at the site root. These are plain-text documentation files designed for AI crawlers. Not a robots.txt. A structured brief that tells AI models what your product is, what it does, who it's for, and how it compares. Think of it as a pitch deck for machines. 2. 62 blog posts before launch. Not SEO filler. Honest comparison posts — my product vs each major competitor. Use-case deep dives. Technical explainers. FAQ content written in the natural question-answer format that AI models actually cite. 3. JSON-LD structured data on every page. FAQPage schema on the homepage, feature pages, use case pages, blog posts. This is the metadata AI models parse when they build their knowledge base. 4. Dedicated pages for every use case and feature. Not just a features list on the homepage. Individual pages at /for/podcasters, /for/game-developers, /features/ voice-cloning. Each with its own structured FAQ. 5. Competitor comparison content that's fair. Not "why we're better." Honest trade-off breakdowns. AI models prefer balanced, cited content over marketing copy. When the AI ranked my product third — not first — that's actually more credible than ranking it #1. This approach has a name: GEO — Generative Engine Optimization. It's early. Most founders haven't heard of it. Most AI tool builders haven't optimised for it either, which is ironic. The core insight: AI models don't read your marketing
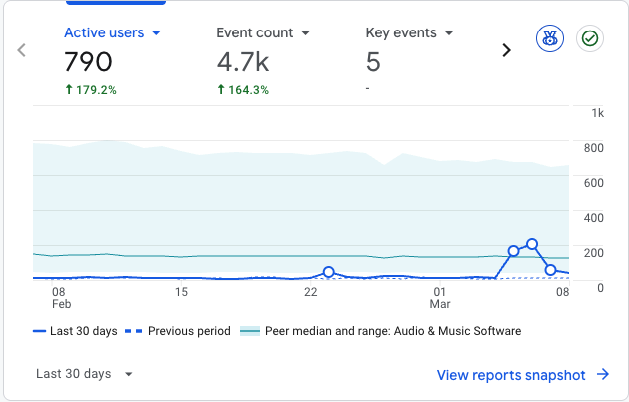
0 likes • Jun 3
@Tuan Hoang Good'ol Google Analytics
0 likes • Jun 3
@Kyle Robichau Glad I could help

May 31 •
Just hit Level 2 and already know exactly what I'm building when I get to Level 3.
I'm running two businesses out of Chesapeake, VA. One is Platypus Automations, an AI automation agency serving local trade businesses in Hampton Roads. The other is a government contract brokering operation where I source federal work and sub it out. Right now my workflow is all over the place. Claude Code open, n8n open, Google Sheets open, session logs, prospect notes, pipeline data. I'm copying and pasting constantly just to keep things connected. What I want to build is one AI OS that ties all of it together. Morning briefing, pipeline status, what to work on, what's overdue, prospect research, outreach drafts, all from one place without touching five different tabs. Anyone here built something similar across multiple business lines? Curious what your setup looks like before I dive into the Level 3 content.
1 like • Jun 1
Thanks for sharing
Apr 24 •
WOW! GPT-5.5 and most awaited Deepseek V4 Flash & Pro dropped today
What a Friday. For two years, if you were building anything serious with AI, you were building on Claude. Not because it was a rule — because it was the right call. Anthropic set the bar for coding. They set the bar for writing. They set the quiet default that if you cared about quality, you paid the Opus premium and didn't ask questions. I didn't either. The whole builder community ran on Claude for a reason. This week, that changed. GPT-5.5 shipped yesterday. DeepSeek V4 Pro shipped the same day. Inside twenty-four hours, the ceiling on agentic coding went up — and the open-weight floor came within striking distance of the closed frontier. Real contenders. Not "almost there." Actually here. Three things this changes for anyone building, and none of them are in the headlines yet. Coding: The default setting of "Claude writes the code, Claude runs the agents" breaks this week. GPT-5.5 is measurably better on the kind of long-running multi-step agent work that used to be Claude's moat. DeepSeek V4 Pro is within a fraction on real software engineering, at a price point where "run it myself" is genuinely on the table. Every tool in your stack that quietly assumed Anthropic — your IDE integrations, your review agents, your automation glue — is about to get reconsidered. That's good for you. Less lock-in. More leverage. Marketing and writing: The price-per-draft math just flipped. We've been rationing the good model forever — the flagship handles the brand-safe stuff, volume work gets the cheap model, and we've all quietly accepted that frontier-quality writing at scale isn't possible. That's over. Frontier-quality writing at open-weight pricing means every ad variant, every email rewrite, every landing-page test, every personalization loop runs at the top tier. The whole architecture of "one good draft, fifty cheap copies" starts feeling as dated as shared creative. Everything top-tier. Everything personalized. Everything testable. Agentic work: This is the one I am most excited about, and the most under-talked-about. For two years, "multi-model agent stacks" has been a slide in decks. Nobody actually builds them, because there hasn't been a real second option. GPT-5.5 for the reasoning step. DeepSeek V4 Pro for the long-context research step. Claude for the interpretive writing step. A cheap open model for the high-volume structured step. Not one runtime. A pipeline. Composed by you. Owned by you. That stops being a slide and starts being the default next month.
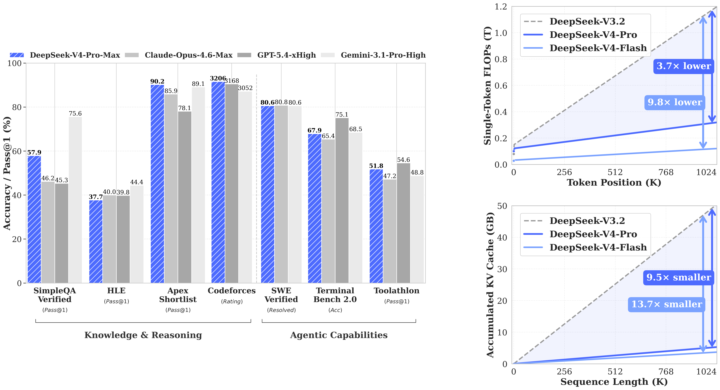
0 likes • Apr 25
@Nigel Vargas true
1 like • Apr 26
@Faaz Khan yeah, I've been deep in the thick of it, and GPT-5.5 does show some promise. I am still due to try out the DeepSeek V4 Pro as soon as it is available on the US inference providers.
Apr 15 •
Anyone played with Andrej Karpathy's "LLM Wiki" idea from the gist he dropped?
Quick version in case you missed it: instead of using RAG to re-chunk your sources every time you ask a question, you compile each source once into a persistent markdown wiki. The LLM extracts concepts, writes entity and concept pages, updates cross-references, flags contradictions, and maintains the whole thing. Future queries read the pre-synthesized wiki. The part that clicked for me: the reason most of us abandon our second brains is that backlink and cross-reference upkeep is boring. The LLM doesn't care. It's happy to touch fifteen pages in one pass. I spent a couple of weeks turning Karpathy's pattern into a Claude Code plugin that actually scales (atomic pages, sharded indexes, BM25 fallback past ~300 pages). It also runs in Codex, Cursor, Gemini CLI, Pi, and OpenClaw through the skills CLI. Install in Claude Code: /plugin marketplace add praneybehl/llm-wiki-plugin /plugin install llm-wiki@llm-wiki Or in any other supported agent: npx skills add praneybehl/llm-wiki-plugin -a <your-agent> Five slash commands (init, ingest, query, lint, stats), stdlib-only Python, no dependencies. Plays well with Obsidian if you want the graph view. Repo: https://github.com/praneybehl/llm-wiki-plugin Karpathy's gist: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f Curious if anyone here has tried the pattern themselves. What did you ingest first, and what broke before it worked?
0 likes • Apr 15
@Frank van Bokhorst great
1 like • Apr 15
@Brian Pfeil nice, the original Autoresearch idea was aimed for improving model performances now the idea has flavours deployed in different agent concepts
1-10 of 10

@praney-behl-3117
Creator, Developer, Entrepreneur, Marketer, Husband & a Dad.
Building Vois.so, konvy.ai, heynyx.app, volant.app and a couple more ;)
Online now
Joined Aug 26, 2025
Melbourne AUS
Powered by