Activity
Mon
Wed
Fri
Sun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
The RoboNuggets Network (free)
52.3k members • Free
Chase AI Community
68k members • Free
Clief Notes
38.2k members • Free
6 contributions to Clief Notes

1h •
Build Once Switch Anytime
I've been integrating ICM into my workflow for the past two months, and I realized something crucial. ICM isn't just about reducing token consumption. It's about making your workflow portable. Once your workflow is built around ICM instead of a specific IDE or LLM, switching between tools becomes almost effortless. That means I can use each IDE and LLM for what it does best. Antigravity for rapid building. Cursor for polishing. Claude Code for deep engineering. Whatever comes next only requires a little tuning instead of rebuilding my entire workflow. The workflow stays the same. The tools become interchangeable.

12d •
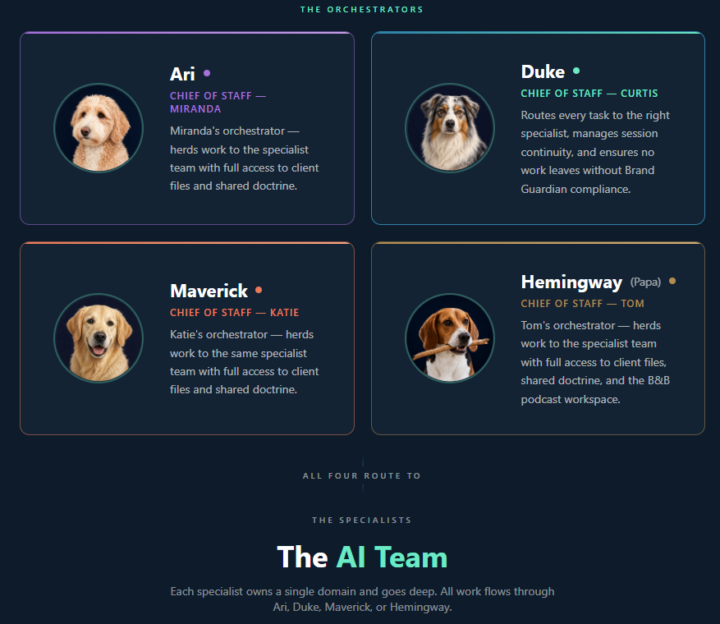
4 Team ICM & Growing
Big update! I brought 2 new team members into our shared workspace today. There are 4 of us all with our own private ICMs with a forked repo for shared files which includes client folders, agents, skills, and doctrine. 2 more team members made the training but skipped setting up their ICMs today. We recorded the session for 3 others that couldn't make it. From start to finish (download of vs-code to fully trained and functioning) completed in 2 hours. By end of June we should have 6-10 team members all in our org using their own personal ICM connected to a shared repo that runs the entire organization. I can't wait to see what these team members start to build for themselves when they start to realize the power they have at their fingertips.
1 like • 12d
@Curtis Hays Amazing. Your high-level architecture is inspiring. One question that immediately came to mind: how do you manage the governance layer as the organization grows? Specifically, how do you handle ownership, reviews, versioning, and quality control for shared doctrine, skills, agents, and workflows across multiple ICMs?

18d •
Workflow vs. Reasoning System: what I've been figuring out (learner perspective)
Most of what I see in here is about automating tasks. Building workflows, connecting tools, making things run faster. I've been learning all of it and it's clicking.But I kept hitting a wall that I couldn't name for a while. I was using an LLM app as my operating system. Not just for tasks but for decision-making, project navigation, thinking through problems, tracking where things stood across different work. And it kept falling apart. Sessions ended, context disappeared, drift compounded quietly. By the time something felt wrong, I was already deep in the wrong direction. I lost real work to it. The problem wasn't the tool. The problem was the category error. A workflow system automates a process you already understand. You know the steps, you know the inputs and outputs, you want to run it reliably and faster. It's execution. It shines when the process is stable. A reasoning system is what you need before that. It's the thinking partner that helps you figure out what the process should even be, especially when you're building something from scratch and the process doesn't exist yet. You can't automate your way to a decision you haven't made yet. I was treating a reasoning tool like a workflow system. No persistent state, no routing logic, no structure, just conversation. It can't hold a project together. That's not what it's for. So I've been building what I'm calling CoworkOS, based on ICM principles, a folder architecture that gives Claude a stable structure to operate within across sessions. Routing tables, layered context files, memory that persists. The idea is: before you build workflows inside your projects, you might need an operating layer that actually runs the reasoning coherently. I don't know if this is the right approach yet. Still figuring it out. But the distinction feels important, especially if you're newer to this and trying to figure out where to start. Workflows are powerful once you know what you're automating. The reasoning layer is what gets you there.
1 like • 16d
Do you see CoworkOS as a temporary scaffold for humans and AI, or as the foundation of an autonomous agent system? My intuition is that once you add persistent memory, routing, and context layers, you're moving from a chat interface toward an operating system for agents.

May 13 •
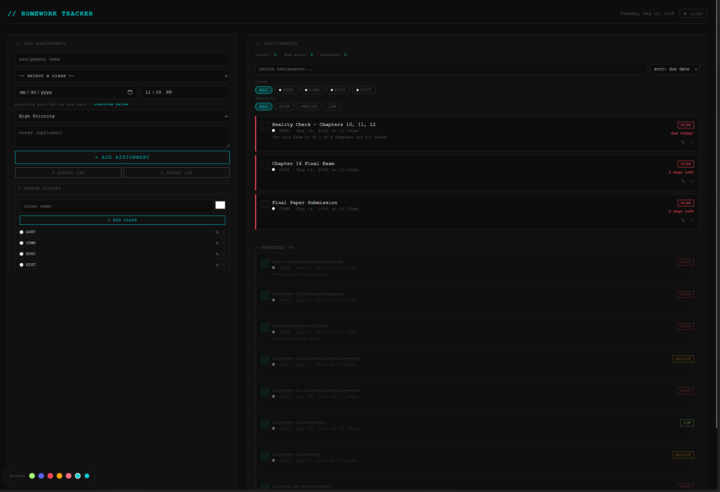
Homework Tracker
My father told me to share this project me and Claude made! Its a homework tracker that has been very helpful for me.
1 like • May 14
This is the kind of AI use case I love seeing, not just experimenting for the sake of it, but solving a real problem with a real outcome. A simple homework tracker might sound small, but if it helps you stay organized, reduce stress, and finish work faster, that’s already a meaningful productivity win. People often focus on flashy AI demos, but the real value appears when AI becomes a practical tool that improves daily life. Big respect to you and your father for building something genuinely useful with AI

May 8 •
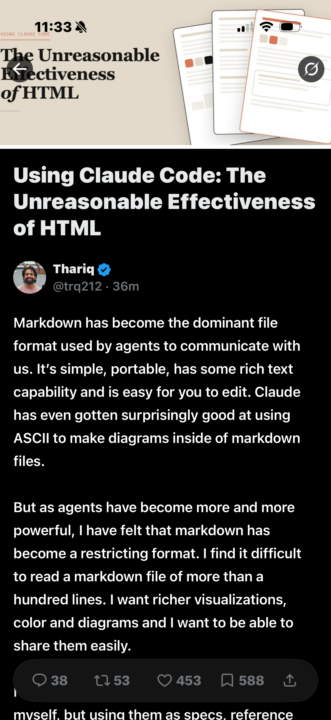
HTML OVER .md Files
A Claude code Eng just dropped this. Anyone been doing this switch yet or will try? Curious to see what @Jake Van Clief has to say. It’s a file still just a different format. Same thing right… thoughts? Pros and cons? Here to learn and discover https://x.com/trq212/status/2052809885763747935?s=46&t=Ayzo8Ebbgb8PZhLNm057bg
1 like • May 11
@Albot Bot | From what I’ve seen, HTML anchors help less than people think for AI agents. Claude is not really “clicking through” documents like a browser. It mostly tries to understand the structure and meaning of the text. Because of that, clean Markdown usually works better than heavy HTML. What helped me more with large reference systems: - smaller focused files instead of one giant REFERENCES.md - clear headings - consistent naming - simple links between notes Example: Instead of one huge file, split it into: - auth-patterns.md - gsap-recipes.md - nft-metadata.md That tends to improve retrieval more than adding HTML anchors. I think HTML anchors are more useful for humans, websites, or automation tools. For agents, the extra markup often adds more noise than value.
0 likes • May 14
@Winter Stree I think the best approach is a hybrid model. Each project should stay mostly self contained because every codebase eventually develops its own architecture, terminology, workflows, and assumptions. Keeping that context local helps prevent agents from carrying unrelated patterns between projects. But I still keep a small shared global layer, mainly for stable standards that should remain consistent everywhere. Something like: - GLOBAL_BRAND.md ; writing style, tone, editorial rules - GLOBAL_ENGINEERING.md ; coding conventions and architecture principles - GLOBAL_AGENT.md ; agent behavior, synthesis rules, referencing strategy Then every project defines its own local source of truth: - CONTEXT.md - DESIGN.md - API.md - BRAND.md So instead of duplicating instructions everywhere, projects inherit a baseline and override what they need locally. That structure scales well because consistency comes from the shared standards, while accuracy stays tied to project specific context. Without that separation, multi project systems usually drift into fragmented instructions where the same rules get rewritten slightly differently across repositories.
1-6 of 6

Active 1h ago
Joined Mar 23, 2026
Powered by