Activity
Mon
Wed
Fri
Sun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
What is this?
Less
More
Memberships
Clief Notes
35.4k members • Free
Ecom Consulting Accelerator
533 members • Free
32 contributions to Clief Notes

13h •
Knowledge extraction pipeline for YouTube videos. Use this on Jake's videos!!!
You watch a lot of content in this space. Demos, walkthroughs, systems builds, production case studies. Some of it is genuinely valuable. Most of it evaporates. A summary gives you a shorter version of what was said. What you want to know is: is there anything here worth keeping, what's the mechanism behind it, and what would you build differently knowing it? What this does: YouTube URL in. Claude extracts 3-7 discrete claims worth keeping. Each one gets: - Concept - the core assertion - Mechanism - the causal explanation (the most important field) - So what - what you'd build or decide differently - Open questions - what this raises but doesn't answer Appended to a local markdown log you own. Real example, from Curtis Hays's Collideascope OS walkthrough: Concept: ICM deploys fast only when the doctrine layer is already documented. The folder structure is the last step, not the first. Mechanism: Curtis had 8 months of prior work before touching the ICM - documented beliefs, brand voice, organizational why/how/what, all in markdown. He brought that corpus in and said "organize it using this structure." The system came together quickly because the content existed. Without pre-existing doctrine, the ICM produces mechanics without a belief layer. So what: Before building the folder structure, ask: is the doctrine layer written down? Cloning a blueprint without existing beliefs produces a technically correct but contextually empty system. That's not in any summary. That comes from extraction. How repo works: Primary mode uses Claude Code with your existing subscription. No API key needed.Three components, each with one job: fetch_ transcript.py gets the transcript, prompts/extract_default.md tells Claude what to look for, CONTEXT.md tells Claude Code how to run the workflow. The prompt file is the thing to edit. The scripts are plumbing.
1 like • 11h
@Greg Prince absolutely, and that's the beauty and chaos of it. we need a way of defining and extracting what's relevant to us specifically, even if its a problem in that moment., across interest domains.
1 like • 10h
@Ruben Aguirre if you don't have the specific experience, this is literally everything you build your foundation from. worth a review or two! The setup isn't perfect but I'm sure this community will build from it!

14h •
Why opus 4.8 thrives in and ICM workspace
I ran Opus 4.8 at max thinking effort this week. The finding isn't "it's smarter." The finding is where that thinking goes, and what it needs before it pays off. Here's what nobody tells you about high-effort reasoning. It only thrives when there's something to reason over. Drop a max-thinking model into an empty context and you get a slow, confident guess. Drop it into a workspace you've actually built, the briefs, the memory, the prior decisions, the evidence, and it does something different. It digs. Three things I noticed. 1. Context is the unlock, not the model. The jump from 4.7 to 4.8 wasn't really "smarter weights." It was better use of the room you give it. The intelligence isn't in the model. It's in the environment you set up before you ask the question. 2. The slow part is the feature. Thinking times went up a lot. That felt like a cost until I read what it was doing. It wasn't stalling. It was hunting through the context for evidence before answering. Judge the reasoning, not the clock. The pause is the work. 3. It reasons evidence-first. This is the real shift. 4.8 goes looking for proof in your context before it commits to an answer. 4.7 tended to answer first, then justify. Working backwards from evidence instead of forwards from a guess changes the quality of everything downstream. It's the best reasoning I've seen from any model, and it only shows up when the evidence is there to find. So the lesson isn't "turn thinking up." Effort and context are a pair. Max effort on a thin context is an expensive guess. Max effort on a built-out workspace is a researcher. Build the room before you ask the question. Full deep-dive available at: https://www.aris-space.com/documents/workspaces/max-thinking-empty-room ASIDE —> After @Ruben Aguirre 's great post earlier today. If you highlight over any AI terminology, it will give you a plain English explanation of what that is. And there's also a glossary at the bottom to help. <3
1 like • 12h
Right back to the foundations Jake taught us. The context system you build is the right and durable abstraction layer to work on. The model is interchangeable as designed.

18h •
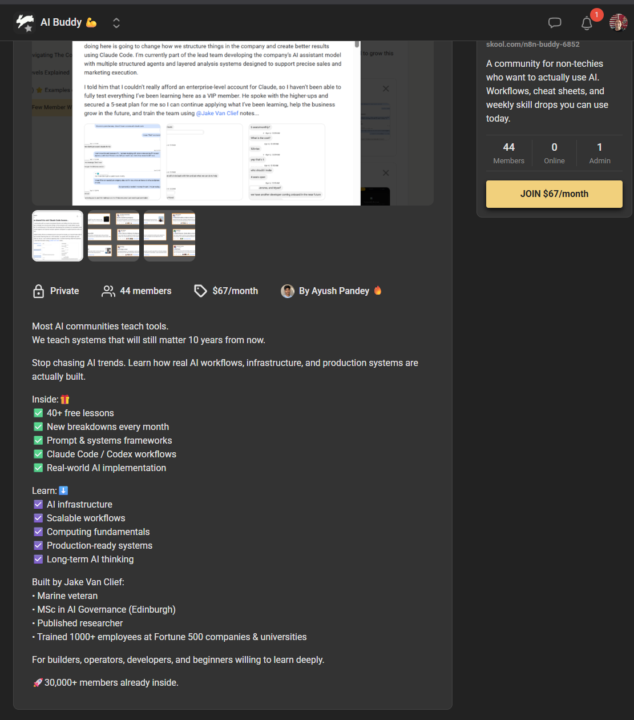
DO RIGHT OR GO BYE BYE!!
So it seems we have a bad actor, I didnt know that Jake was another person?? I am highlighting this because, if we catch you, we will report you to Skool, this is considered fraud when impersonating someone else, on top of charging people for our content we work hard here developing in the community. You have no right to do that, and its a shame someone is doing this. DO RIGHT OR GO BYE BYE. The choice is yours. Until next next time Friends. Aaron
1 like • 17h
did this guy seriously copy paste the whole course

1d •
🚨 You've been asking when the Lyceum opens. The waitlist is live. 🚨
The waitlist is up and seats are limited, so this is your nudge to go lock yours in. 👇 New here? Quick context. 👀 The Lyceum is Jake's live cohort program built on ICM, the methodology 35,000 people in this community are already using to get real results with AI. The short version: folders over agents. You learn the layer underneath the tools, the one that keeps working when the next model drops. Full breakdown is on the site. Here's what's inside: 🎯 Three cohorts, Technical, Business, and Creator. Same methodology, built around what you actually do. 🎥 Live sessions with Jake and a full team of instructors. ♾️ Lifetime recordings, written curriculum, and a private cohort Discord. 📜 An Eduba ICM certification you can put on your resume. And a guarantee no course makes: ✅ You leave with a working product, or the team finishes it with you. ⏳ Seats are limited and this community moves fast, so the math is not in your favor if you wait. 💡 Pricing and start dates aren't public yet. The waitlist sees them first, gives feedback on timing, and gets in before the program opens. Everything you want to know is on the page. If you already know this is for you, get on it. 🔥 👉 https://lyceum.eduba.io
0 likes • 17h
This sounds like AI Hogwarts. The Lyceum.

5d •
Do you talk to people outside the community about AI?
At a going away party this weekend, I was talking to some government workers who mentioned they're mandated to use Copilot at work every day. Naturally curious I asked, "Oh what do you use it for?" They both sheepishly admitted that they don't. "We just don't see how it's useful for what we do." Later that night: birthday dinner at a German restaurant I'd been trying to get to for years. Some old theater colleagues: a props artisan, a lighting designer, they spend their days with hands-on physical work. AI didn't come up once. Meanwhile I was sitting at the table quietly asking Claude to translate the menu. It didn't just give me definitions — it told me the story behind one of the dishes. Monks during Lent, hiding meat inside pasta to get around fasting restrictions. Made for a very fun conversation topic but nobody noticed I had found out from Claude. It's very interesting being inside this bubble of thinking about how to make the most of AI all the time and finding that everybody else seems to just not care. A small win though, my brother got a Claude subscription this weekend. I've been sharing with him what I've been able to do with what I've learned here and it took him a bit to get over the hurdle of paying for a subscription (he's very frugal), but after a day auto-transcribing a jazz improvisation recording straight to sheet music, he's already organizing his context with folders and texting me about projects he wants to build. How is everyone else finding how people outside the community talk about AI?
0 likes • 19h
@Roc Lee Much appreciated! I've been trying to build a project i call MacroMachine. It's a data pipeline that pulls macro economic indicators and asset price data, runs it through a set of signals, and tells me where we are in the macro cycle and what that means for how a portfolio should be positioned. Long term goal is a dashboard I can use day to day and eventually build a service around. The wall I hit was my workflow. I was running reasoning sessions through GPT with a system state JSON and five context docs, then executing task briefs in VS Code with Copilot. Worked until it didn't. Sessions drifted, context got messy, the project got harder to trust. Built in the wrong direction for a while before I noticed. That's what brought me here. Now recalibrating with ICM principles.
1 like • 19h
@Ruben Aguirre Exactly. You realize pretty quickly how much you don't know, which is actually the best place to be. Beats thinking you've got it figured out!
1-10 of 32

@daniel-terry-8872
The vision = Macroeconomic AI analysis across major assets. MacroMachine.
Let's connect on LinkedIn!
Active 8h ago
Joined May 13, 2026
Palm Harbor, FL 34685, USA
Powered by