Activity
Mon
Wed
Fri
Sun
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
What is this?
Less
More
Memberships
Fabric Forge
1k members • Free
Learn Microsoft Fabric
15.3k members • Free
22 contributions to Learn Microsoft Fabric

6d •
How are your data engineers positioned within the business?
Quick question for the group: How are your data engineers positioned within the business? In our proposed model, IT is responsible for extracting and landing source data into Bronze (raw/delta) in a Fabric Lakehouse, while data engineers sit closer to the business and own Silver and Gold transformations, including semantic/analytical modelling. Keen to hear how others have structured this in practice and what’s worked (or not).

0 likes • 2h
I am in the IT department, but we have a dual role, I take care of the ingestion as well as working with our business analyst to turn bronze into gold

🚀
3d •
🎥 [New recording] February 2026 - Community & Product Updates
𝗙𝘂𝗹𝗹 𝗿𝗲𝗰𝗼𝗿𝗱𝗶𝗻𝗴 𝗼𝗳 𝘁𝗵𝗶𝘀 𝗹𝗶𝘃𝗲 𝘀𝗲𝘀𝘀𝗶𝗼𝗻 𝗶𝘀 𝗻𝗼𝘄 𝗮𝘃𝗮𝗶𝗹𝗮𝗯𝗹𝗲: 👉 #February 2026 - Community & Product Updates ... thanks to everyone that joined us LIVE! Welcome to the second Cross-Community Monthly Update of 2026! Each month, I'll be populating this post, with updates from all the Communities/ Channels I manage, PLUS updates from the Fabric Product Team from the recent January 2026 Product Updates - new features. I hear from lots of people that it's difficult to keep up-to-date with Fabric and all the constant changes, so hopefully this will serve as a useful resource for tracking what's changing, and what's important. As always, your feedback is very welcome! In this post, we'll cover: - Learn Microsoft Fabric Community Updates - Fabric Dojo Community Updates - Microsoft Fabric - Product Updates for this month. - Announcements (coming soon) 🟩 Learn Microsoft Fabric Community Updates - Well done to Srini , Nadir , Subramaniyam , Mehari , Pooja , Amit , Pius , Amit B , Craig , Raphael, Chandini , Ankur , Niroshana , Nneka , (and all others I haven't mentioned) for passing their certification exams this month!
0 likes • 2h
Cheers thanks for this!

Sep '25 •
Finally, MERGE Statement Will Be Supported in Fabric DW
Microsoft Fabric Data Warehouse now supports the powerful MERGE statement, streamlining data sync operations. It enables seamless INSERT, UPDATE, and DELETE logic in one atomic block—ideal for SCD and ETL workflows. This long-awaited feature simplifies code, boosts performance, and aligns Fabric DW with enterprise SQL standards. A major win for data engineers—Fabric just got more intuitive, efficient, and migration-friendly! Why MERGE Matters The MERGE statement allows you to: Synchronize staging and target tables in one atomic operation Handle Slowly Changing Dimensions (SCD) with ease (Types 0, 1, and 2) Simplify ETL logic by combining INSERT, UPDATE, and DELETE into a single block Reduce code complexity and improve performance in large-scale transformations
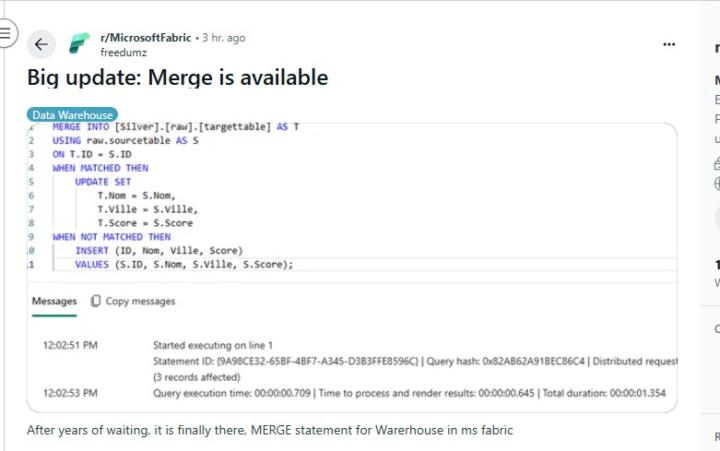
0 likes • 22d
Is merge now GA? I am trying to find information about it and some sources say it is as of 11/25, but I wasn't easily able to find MS resources?
0 likes • 17d
@Will Needham That is what I thought as well, the topic title made my hope go up, but I'll have to wait a bit longer it seems :-)
🚀
Jun '25 •
Using ChatGPT/ LLMs for learning Fabric (be careful!)
I get it, it's an attractive proposition. Type any technical question into a chat window and get an instant response. Unfortunately (at the moment), it's not quite as simple as that. I think we all know that ChatGPT & other large language models (LLMs) can hallucinate, i.e. confidently giving you answers that: - are wrong - are misleading - were maybe right 6 months ago, but now the answer is irrelevant/ not accurate. With Fabric, they are a few factors that increase the likelihood of hallucinations, that you need to be very aware of: - Fabric is fast moving - things change weekly, monthly. Therefore a feature/ method/ piece of documentation that was used in the last LLM training run 6 months ago, might no longer be relevant, or new features have superseded previous approaches. - Fabric is the evolution of previous Microsoft data products. This is good in some ways, but catastrophic for LLMs (and learners relying on LLMs). There is vastly more training data out on the internet for Azure Data Factory, for example, than Fabric Data Factory. Or Azure Synapse Data Engineering over Fabric Data Engineering. And yes there are similarities for how the old tools work vs the new tools, but you need to be super careful that the LLM generates a response for FABRIC Data Pipelines, rather than Azure Data Factory pipelines, for example. Or generates Fabric Data Warehouse compliant T-SQL code, rather than Azure SQL code. This is very difficult, unless you have knowledge of how both products work (which most learners/ beginners don't!). I'm not saying don't use LLMs for studying, just that you need to be super careful. I can think of two use cases that are lower risk, using LLM+Fabric for Spark syntax & KQL syntax generation. That's because Spark and KQL are very mature ecosystems, with lots of training data on the internet, and their syntax won't change too much over the months and years. Fabric Data Warehouse T-SQL code generation is more tricky/ risky because the way the Fabric Data Warehouse works is quite different to a conventional SQL Server (which is what most of the training data will be based on).
0 likes • Aug '25
Spot on Will! I do use them, but only for specific, detailed sets (like here is a json snippet, how do i use cross join etc). I dont tend to use them to create complete sets of SQL code start to finish. For pure fabric questions i will use it in a manor like "Explain to me how the outlook activity works in a fabric pipeline"
May '25 •
Delay between a lakehouse and it SQL analytics endpoint
Hi All, A know issue is the fact that when I ingest data into a lakehouse, there can be (nah will be :)) a delay before that data is actually available in the SQL analytics endpoint. Up until now I have been trying to tackle this by adding 5 or even 10-minute delays between lakehouse ingestion steps and addressing the SQL endpoint to do joins to dim tables, ETL etc. This works most the time but of course causes delays in running pipelines (and it is not 100% proof). I came across the below MS article, has anyone tried this yet and is it really as simple as adding a script activity in the pipeline along the lines of: "SELECT TOP(1) 1 FROM [lakehouse].[dbo].[tablename]" Or should i read all rows, like SELECT 1 and not top (1) ? https://learn.microsoft.com/en-gb/fabric/known-issues/known-issue-1092-delayed-data-availability-analytics-endpoint-pipeline?wt.mc_id=fabric_inproduct_knownissues Cheers Hans
1-10 of 22

Active 1h ago
Joined Aug 9, 2024
Powered by