Activity
Mon
Wed
Fri
Sun
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
What is this?
Less
More
Memberships
Paid Traffic & Automations
272 members • Free
AI Business Builders
824 members • Free
AI Automation Made Easy
16k members • Free
Automate Business AI
5.8k members • Free
AI Workshop Lite
20.4k members • Free
Automation-Tribe-Free
4.3k members • Free
Nexus 6 Systems
27 members • Free
SW Automation
8.3k members • Free
AI Automation Society
340.6k members • Free
3 contributions to AI Automation Society

May '25 •
Mcp & sonnet 4
Hi everyone,I'm currently trying to integrate Claude Desk with an MCp in n8n. I'm running into an issue where the MCP doesn't seem to be recognized or queried properly from Desk. I'm using Sonnet 4 (the free version), and I was wondering: is it only possible to query an MCP from Desk if you're using Sonnet 3.7 (which requires a paid plan)? Could that be why the MCP isn't being accessed correctly? Thanks in advance for any help! Emanuele
0 likes • May '25
@Mirko Salzer hi I use Anthropic
May '25 •
cURL Button Missing in HTTP Request Tool (inside AI Agent)
Hi everyone 👋 I'm currently working with an AI Agent in n8n and noticed something odd about the HTTP Request tool integration. 🔍 When I use a regular HTTP Request node in a workflow (see point 1 in the image), I can see and use the “Import cURL” button just fine. However, when the HTTP Request is used as a tool inside an AI Agent (point 2 in the image), the “Import cURL” button is missing from the UI. This makes it harder to quickly debug or copy the request. I’m on n8n version 1.85.4, which I believe is recent enough to include this feature. I’ve also seen in some webinars that the cURL button should be available even for HTTP tools inside agents. ➡️ Is this a known limitation or a bug?➡️ Has anyone managed to get the cURL button to show in this context? Thanks in advance! Emanuele
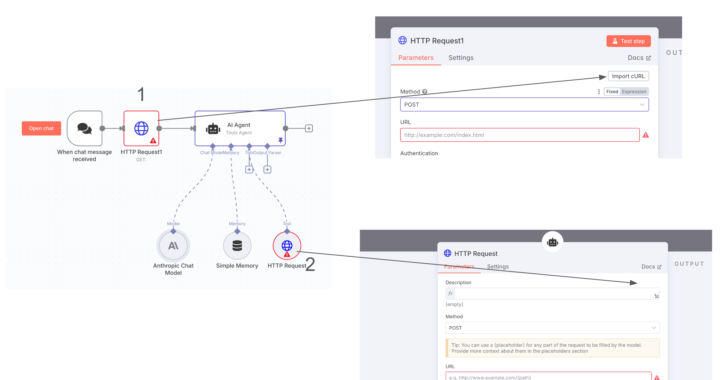
0 likes • May '25
Thankyou Talha, I've just see that the new feature is available in the version 1.90.0 so I think I will update😀. Emanuele
May '25 •
How to Queue and Rate Limit LLM Calls in n8n (One Request per Minute from Batch)
Hi everyone, I’ve built a workflow where, given a company’s industry code, an LLM generates a sector analysis and updates a specific field in our CRM. My problem is that there could be multiple bulk requests happening at the same time, and I want to implement a queue system to avoid hitting the LLM's token-per-minute limit. I tried using the Batch node to create a queue, which works in grouping items, but I can’t manage to enforce a fixed interval of one request per minute. Is there a reliable way to process one item from the batch every 60 seconds? Would love suggestions or patterns you've used to handle this kind of isssue with LLMs inside n8n! Thanks in advance 🙏 Emanuele
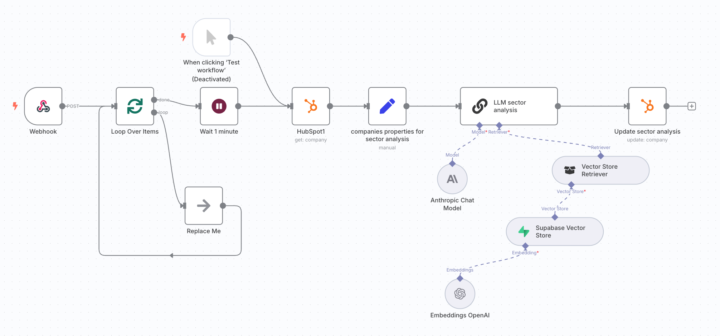
0 likes • May '25
@Mouen Khan Hey! Great suggestion, but just a heads-up:The pattern with Split In Batches + 60s Wait does create internal queuing within a single workflow execution, but it doesn’t enforce a global rate limit between executions of the agent if multiple instances of the workflow are running in parallel. In other words:It works if the workflow runs sequentially. It does not actually control the global frequency (e.g., 1 request per minute to an agent or endpoint) if there are multiple triggers or concurrent users, like in webhook scenarios.
0 likes • May '25
@Mirko Salzer Hi! Externalizing the timing really does seem like the only solid solution here. I’ll go ahead and test it out, and I’ll share the results in the post. See you soon! 🚀
1-3 of 3

@emanuele-robba-4016
I'm excited to join this community! I'm passionate about AI automation and currently exploring how to integrate tools like n8n with GPT
Active 44d ago
Joined Mar 31, 2025
Powered by