Activity
Mon
Wed
Fri
Sun
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
What is this?
Less
More
Owned by Diane
Under Construction
Memberships
Scaling Founders AI
10 members • Free
AI Automation Society
352.2k members • Free
AI for Life
28 members • $297
Synthesizer: Free Skool Growth
41.5k members • Free
Brand Sharks
504 members • Free
AI Automation Society Plus
3.6k members • $99/month
Skoolers
192.6k members • Free
🇺🇸 Texas IRL
433 members • Free
ACQ VANTAGE
914 members • $1,000/month
46 contributions to AI for Life

🔥
3d •
News: Anthropic confirms three bugs degraded Claude Code [Fixed]
Anthropic on Wednesday published a detailed post-mortem acknowledging that three separate product-layer changes caused weeks of quality degradation in Claude Code, its flagship AI coding tool, vindicating developers who had spent weeks insisting the product had gotten worse. The company traced the issues to a reasoning effort downgrade, a caching bug that wiped session memory on every turn, and an overly aggressive system prompt designed to curb verbosity. All three changes were shipped independently between early March and mid-April, but their overlap in time created what appeared to users as broad, inconsistent performance decay. The first change landed on March 4, when Anthropic lowered Claude Code's default reasoning effort from high to medium to reduce latency. The company's internal evaluations suggested the trade-off would yield only "slightly lower intelligence," but users noticed immediately. Anthropic reverted the change on April 7, calling it "the wrong tradeoff" in the post-mortem. The second issue was a caching bug introduced on March 26. An optimization intended to clear old reasoning blocks once upon session resume instead triggered on every turn, effectively erasing Claude's working memory for the remainder of any affected session. The bug also caused faster-than-expected usage limit depletion, as each request became a cache miss. Anthropic acknowledged the bug "made it past multiple human and automated code reviews, as well as unit tests, end-to-end tests, automated verification, and dogfooding." It was fixed on April 10. The third regression arrived on April 16, when Anthropic added a system prompt instructing Claude to keep responses between tool calls to 25 words or fewer — a response to the chattiness of the newly launched Opus 4.7 model. Internal testing later showed the instruction caused a roughly 3% drop on coding evaluations. It was reverted on April 20. Compensation and New Controls As remediation, Anthropic is resetting usage limits for all subscribers and rolling out several process changes: broader internal dogfooding on public builds, enhanced per-model evaluation suites, stricter system prompt auditing, soak periods for any change that could affect intelligence, and gradual rollouts. The company also launched a dedicated @ClaudeDevs account on X to provide more transparency around product decisions.
Poll
5 members have voted
![News: Anthropic confirms three bugs degraded Claude Code [Fixed]](https://assets.skool.com/f/f1f8713c199d4c3b994a02e649d607de/1c58b6e963594b2fb4b028a9a6d98ccce4f823d66aa34523bc920ccef9675b72-md.png)

🔥
1 like • 2d
Really wild!
🔥
0 likes • 2d
@Matthew Sutherland thank you! Appreciate you!
🔥
4d •
Claude Code Pro User Workflow
* Confidential. Use, Do not share.* Thank you! Pattern from a real session this week. When you're using AI to build AI tools, one agent is not enough. Self-review fails the same way self-driving fails: the thing that produced the error reproduces it during review. The fix is three roles, not two: The Executor does the work. Full autonomy inside clear rules. Stops only when it genuinely can't decide. The Critic reviews the work. Same model, different posture: read, verify, find what's wrong, recommend PROCEED, FIX, or ASK. The Operator (you) reads the critic's recommendation, not the raw work. Approves on PROCEED. Intervenes on ASK. Out of the loop on tactical review. Bonus fourth role I didn't have a name for until this week: a Strategic AI in a separate chat, used for direction calls outside the work. "Are we in a rabbit hole." "Is this rigor right." Operates on the work itself, not in it. The unlock isn't capability. It's posture. Same model, three system prompts, three different jobs.
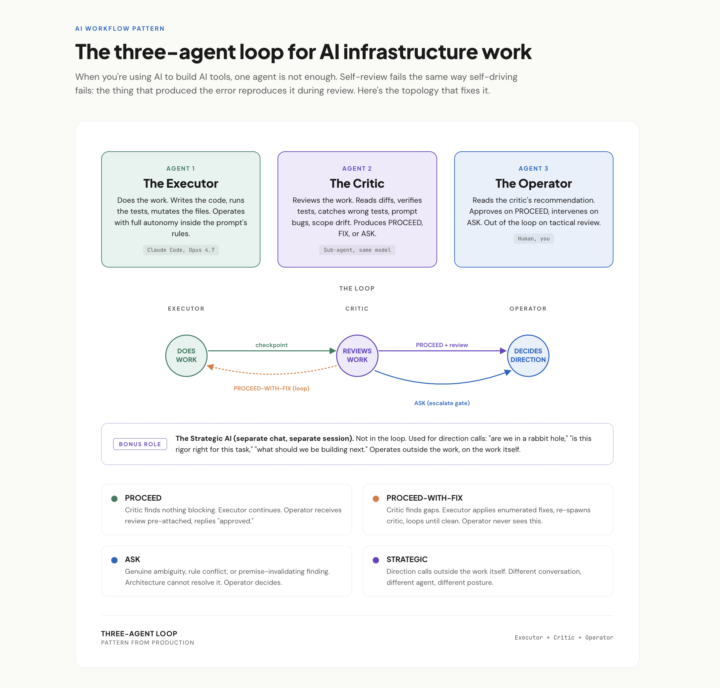
🔥
1 like • 3d
LOVE IT! Gold!
🔥
1 like • 3d
@Matthew Sutherland 🚀
🔥
6d •
Testing New Logo
Taking advantage of ChatGPT's pretty amazing image gen.
Poll
2 members have voted
🔥
1 like • 5d
@Matthew Sutherland more options please...
🔥
1 like • 5d
#2
🔥
7d •
GSD 2.0: Read This Before You Pay for Tokens
There's a new tool making the rounds called GSD 2.0. (Launched in early March 2026) The pitch sounds incredible: type one command, walk away, come back to a built project. Autonomous coding agent. Crash recovery. Cost tracking. The works. I went deep on it this week. Here's the part the hype tweets are skipping. What GSD 2.0 actually is The original GSD was a clever set of prompts you'd plug into Claude Code. It worked, but it was a prompt layer on top of Claude Code. GSD 2.0 is a different beast. It's a standalone application that runs the AI agent itself. You don't run it inside Claude Code anymore. You run it instead of Claude Code. That's the headline change, and it's the detail getting lost in the excitement. It manages git branches for you. It splits work into chunks small enough to fit in one conversation window. It retries when things break, recovers from crashes, and tracks every dollar you spend. On paper, it's serious engineering. Where the cost actually hits GSD 2.0 charges you per token. Same way you'd pay if you used the raw Anthropic API. If you have a Claude Max subscription, the $100 or $200 a month flat-rate plan that powers Claude Code, you already get effectively unlimited AI usage for one fixed price. Developers have publicly reported burning five figures of API spend in months that cost them $200 on Max. GSD 2.0 doesn't use your Max subscription. It bills directly to the API. It gets worse. GSD 2.0 is structurally more expensive per task than Claude Code, by design. It throws away the conversation history between every task to keep things "clean." That sounds great until you learn that the recycled conversation history is exactly the thing that makes Max so cheap. With Max, you pay nothing extra to reuse context. With GSD 2.0, you pay full price for it again every single task. Real numbers A small project on GSD 2.0 will cost you somewhere between $15 and $50 in API charges. A medium project, $40 to $150. A gnarly one with retries and crashes, several hundred dollars. None of that is covered by your Max plan.

🔥
1 like • 7d
@Matthew Sutherland great read, thank you for testing it out! It sounds worth it for the right projects, deciding what projects are right is another animal! Appreciate you, your dedication, skill, and heart you pour into these reads!
🔥
0 likes • 7d
@Matthew Sutherland very interested in how it goes!
🔥
10d •
Opus 4.7: 10 things that actually matter
A practitioner read on the April 16, 2026 release. Numbers cited are from Anthropic’s system card or named partner benchmarks. ## 1. Coding is the real jump SWE-bench Verified 80.8% → 87.6%. SWE-bench Pro 53.4% → 64.3%. CursorBench 58% → 70%. Anthropic’s internal 93-task benchmark reports a 13% lift across the suite. Rakuten’s partner eval claims 3x more production tasks resolved vs 4.6. On multi-file work, fewer back-and-forth loops and more one-shot fixes. ## 2. Agents run shorter and cleaner Long-running loops reason more before acting. Notion AI reports ~14% improvement on multi-step workflows at one-third the tool errors. Box’s figure: average calls per workflow dropped from 16.3 (4.6) to 7.1 (4.7). Fewer decisive steps instead of noisy chatter. ## 3. Vision is finally usable for screenshots Resolution 1,568px (1.15MP) → 2,576px (3.75MP) on the long edge, roughly 3x. XBOW visual-acuity 54.5% → 98.5%. OSWorld-Verified computer use 72.7% → 78.0%. This is the change that actually unlocks dense-UI automation, diagram parsing, and screenshot-based QA. ## 4. Still 1M context Context window and output limits match 4.6. Pipelines built around long documents or extended chains don’t need architectural changes. Self-verification is better, so coherence over long multi-step runs holds up longer. ## 5. Honesty and safety moved the right direction Reduced hallucinations and sycophancy, tougher against prompt injection. Good for client-facing systems. Note: 4.7 is also more conservative around offensive security work. Anthropic launched a Cyber Verification Program for approved red-team use cases. ## 6. Sharper codebase understanding CodeRabbit reports more real bugs found, more actionable reviews, and better cross-file reasoning than any model they’ve evaluated. The model builds a more persistent internal map of a repo instead of brute-forcing every file. Claude Code also shipped a new `/ultrareview` command for dedicated review passes. ## 7. New xhigh effort tier

🔥
0 likes • 10d
@Matthew Sutherland I may be trying to get it to do something it just sucks at though... not its wheelhouse.
🔥
0 likes • 10d
@Matthew Sutherland rethinking my strategy
1-10 of 46

Active 11h ago
Joined Feb 20, 2026
Texas