Activity
Mon
Wed
Fri
Sun
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
What is this?
Less
More
Memberships
Clap Academy Digital Community
497 members • Free
66 contributions to Clap Academy Digital Community

Oct '23 •
Power BI Training - Day 1
Last Monday was the first day for Power BI Training. It was about the introduction and what we understand as Power BI. I learnt about how to download Power BI desktop on the computer system, different functions of the tabs/menus, 3 different views of Power BI (report view, table view & model view).

0 likes • Nov '23
Amazing Visualization tool. Even after months of familiarizing myself with Power BI, I still discover new features

Nov '23 •
Join the ChatGPT Revolution: Create Your Account Today!
Hello everyone, I trust you're all doing well! I'd like to encourage those who haven't yet explored ChatGPT to consider creating an account at chat.openai.com. Signing up is a straightforward process and gives you access to the innovative features of ChatGPT 3. Additionally, you have the option to join the waiting list for an upgrade plan, with no immediate charges involved. Having a ChatGPT account is increasingly becoming as essential as having an email address. It's a valuable tool for various tasks and learning opportunities. So, if you haven't already, take a moment to create your account today. Thank you!
2 likes • Nov '23
Quintessential tool in the Analyst's arsenal..

Oct '23 •
Order of SQL Query Execution
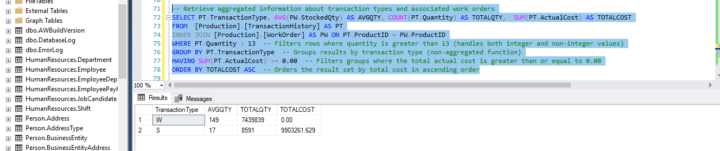
The sql query below is based on the Advertureworks2019 database we loaded into our database during SQL class. -- Retrieve aggregated information about transaction types and associated work orders SELECT PT.TransactionType, AVG(PW.StockedQty) AS AVGQTY, COUNT(PT.Quantity) AS TOTALQTY, SUM(PT.ActualCost) AS TOTALCOST FROM [Production].[TransactionHistory] AS PT INNER JOIN [Production].[WorkOrder] AS PW ON PT.ProductID = PW.ProductID WHERE PT.Quantity > 13 -- Filters rows where quantity is greater than 13 (handles both integer and non-integer values) GROUP BY PT.TransactionType -- Groups results by transaction type (non-aggregated function) HAVING SUM(PT.ActualCost) >= 0.00 -- Filters groups where the total actual cost is greater than or equal to 0.00 ORDER BY TOTALCOST ASC -- Orders the result set by total cost in ascending order Each query begins with finding the data that we need in a database, and then filtering that data down into something that can be processed and understood as quickly as possible. Because each part of the query is executed sequentially, it's important to understand the order of execution so that you know what results are accessible where. Query order of execution 1. FROM and JOINs The FROM clause, and subsequent JOINs are first executed to determine the total working set of data that is being queried. This includes subqueries in this clause and can cause temporary tables to be created under the hood containing all the columns and rows of the tables being joined. 2. WHERE Once we have the total working set of data, the first-pass WHERE constraints are applied to the individual rows, and rows that do not satisfy the constraint are discarded. Each of the constraints can only access columns directly from the tables requested in the FROM clause. Aliases in the SELECT part of the query are not accessible in most databases since they may include expressions dependent on parts of the query that have not yet executed. 3. GROUP BY The remaining rows after the WHERE constraints are applied are then grouped based on common values in the column specified in the GROUP BY clause. As a result of the grouping, there will only be as many rows as there are unique values in that column. Implicitly, this means that you should only need to use this when you have aggregate functions in your query.
0 likes • Oct '23
Great material! Thanks
Sep '23 •
Effective Strategies for Handling Missing Values in Data Analysis (Updated 2023)
Hi Team, In the quest for a career in data science, mastering the art of handling missing values in datasets is crucial. Missing data is a ubiquitous issue that can significantly skew the outcomes and diminish the precision of machine learning models. This article delves into the intricacies of missing data, its types, and the reasons behind its occurrence. Additionally, it provides practical techniques for addressing lacking values, illustrated with dataset examples. Indeed, for an in-depth understanding and actionable insights on tackling missing data in your data science journey, read the full article here: [https://www.analyticsvidhya.com/blog/2021/10/handling-missing-value/#:~:text=Replacing%20with%20the%20mean,need%20to%20be%20treated%20first]. This comprehensive guide will arm you with the knowledge and skills needed to enhance the accuracy of your machine learning models.
0 likes • Oct '23
Very important article I believe for data Analysts
Sep '23 •
Team Voltron Update
On Monday afternoon, Team Voltron finalized the project’s visualization needs. We then gave each page a name that matched the corresponding visualization and aligned with the project requirements. We plan on meeting on Tuesday again to complete cosmetic adjustments on our visualizations. The evening class marked the beginning of a new Excel Class. The lecturer Olive introduced those in attendance to Excel as a foremost spreadsheet software that is a critical tool in the Data Analyst's arsenal. We covered the basics like the different parts of the ribbon, naming a cell and basic functions like SUM, PRODUCT. We closed out with an assignement to pick a theme and go through the different templates to familiarize ourselves with Excel.
8
0
1-10 of 66

@ahmed-siewe-3216
I am an entrepreneur at heart! I've worked as a Network technician in the US, ran a chicken farm in Cameroon and started an NGO for at risk women
Active 674d ago
Joined Jul 6, 2023
Douala, Cameroon