Activity
Mon
Wed
Fri
Sun
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
What is this?
Less
More
Memberships
IYAD ACADEMY
43 members • Free
AI Automation (A-Z)
154.1k members • Free
AI Automation Agency Hub
316.4k members • Free
AI Automation Mastery
29k members • Free
Ai Bdarija
4.1k members • Free
AI Automation Society
363k members • Free
Automation Masters
3.8k members • Free
9 contributions to AI Automation Society

10h •
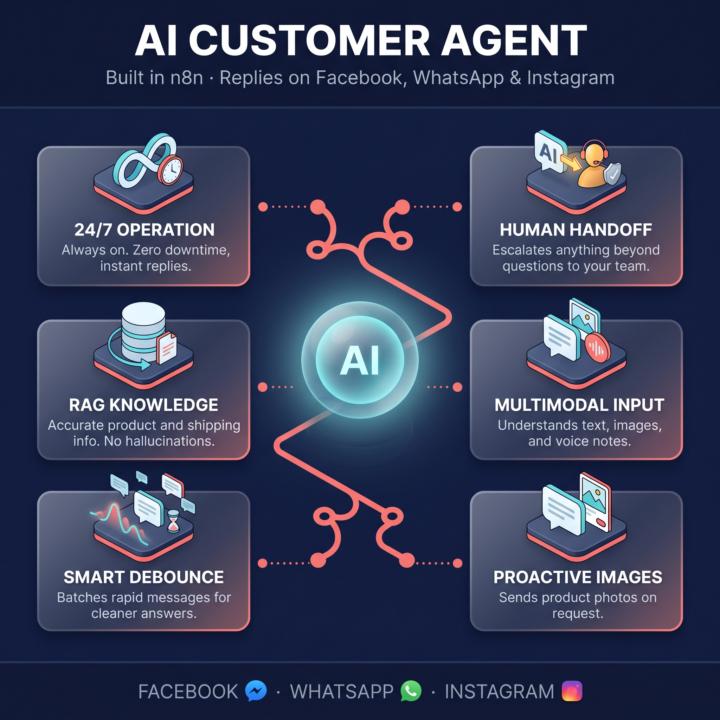
Most business owners misunderstand what a chatbot is for.
They think it's there to replace their team. It's not. A chatbot's job is to answer questions — fast, accurately, at any hour. That's it. The moment a customer needs judgment — a complaint, a custom order, an edge case — a human has to step in. That's not a flaw. That's the design. Here's the architecture I build in n8n that respects that boundary: → 24/7 OPERATION — always on, no after-hours gap → HUMAN HANDOFF — escalates anything beyond questions to your team → RAG KNOWLEDGE — pulls real product & shipping info from your own docs → MULTIMODAL INPUT — reads text, images, and voice notes → SMART DEBOUNCE — waits, batches, then answers like a human → PROACTIVE IMAGES — sends product photos when asked The point isn't to replace your team. It's to free them from answering "do you ship to my city?" 200 times a day, so they can handle what actually matters. I've shipped this for stores in fashion, electronics, and home goods. If you want me to break down a specific piece, drop a comment — happy to walk through it. #n8n #AIAutomation #WhatsAppBusiness #Ecommerce #CustomerExperience
0 likes • 4h
@Muskan Ahlawat I totally agree—Voice AI takes engagement to a whole new level.
0 likes • 4h
@Nigel Vargas Exactly. The goal isn't to automate the human out of the loop, but to elevate their role. By letting the AI handle the repetitive 80%, we ensure that when a human does step in, they are focused on high-value tasks—building trust and solving complex edge cases that require real empathy. It’s about ROI on human time, not just cost-cutting.
Mar 26 •
Building the 2026 AI Stack: Zapier, Make, n8n, or Claude Code? 🛠️🧠
As an automation engineer, I’m constantly looking for the most efficient way to bridge the gap between "AI thinking" and "Business doing." I see a lot of people sticking to one tool, but after researching the current landscape, it's clear that the "perfect" stack actually depends on your scale. Here is my honest take on the options I'm evaluating for my latest projects: Zapier: The "It just works" option. Great for beginners or simple 1-step tasks. But as you scale, the "Task Tax" starts to eat into your margins. Make: The visual middle ground. Better for complex logic and much more affordable than Zapier at scale, but you're still locked into their cloud. n8n: This is where I’m spending most of my time. It’s "fair-code," meaning I can self-host it for total data privacy and zero "per-task" fees. If you're building deep AI workflows (RAG), the technical control here is unmatched. Claude Code (The Newcomer): Unlike the others, this is an "Agentic" tool that lives in your terminal. It doesn't just connect apps; it can actually write, test, and fix the code inside your automations autonomously. My Strategy: Use n8n as the "brain" for business operations and Claude Code as the "engineer" to build and maintain the custom logic. I’m curious—especially for those running high-volume businesses—what does your automation stack look like right now? Are you sticking with the simplicity of Zapier/Make, or are you moving toward the control of n8n and Claude Code? Let’s talk shop in the comments! 👇
4
0
Mar 25 •
Why your AI is lying to your customers (and how RAG fixes it) 🧠❌
We’ve all seen it: You build a "custom" AI agent for a client, and it starts hallucinating. It makes up pricing, promises discounts that don't exist, or gives generic advice that sounds like a Wikipedia entry from 2021. Most founders think "Fine-Tuning" is the answer. It’s not. Fine-tuning is slow, expensive, and your model is outdated the second your data changes. If you want an AI that actually knows your business, you need RAG (Retrieval-Augmented Generation). The Concept: Think of a standard LLM as a genius student taking an exam from memory. They might get the facts mixed up. RAG is that same genius student taking an "Open Book" exam. They have a massive library (your data) right behind them and look up the exact page before they ever speak. How I’m building this in n8n: 1. Vector Embeddings: I take a company’s raw data—knowledge bases, PDFs, or live Google Sheets—and turn them into mathematical vectors. 2. Semantic Retrieval: When a user asks a question, my n8n workflow doesn’t just ping the LLM. It first queries a Vector Database (like Pinecone or Supabase) to find the exact relevant context. 3. Augmented Prompting: I feed that specific data into the model and tell it: "Only answer using this factual context." The Result: No more hallucinations. Just a 24/7 AI agent that actually knows your SOPs, your inventory, and your specific business logic. I’m currently deploying this architecture for my automation clients to handle high-stakes customer support and internal knowledge management. For the builders here: Are you still fighting with 5,000-word system prompts, or have you made the switch to a Vector DB yet? Let’s talk shop in the comments! 🛠️👇
Mar 24 •
n8n skills leveled up 🟢 Ready for projects!
Hey Skool community! Quick update from my end—I’ve officially transitioned from "learning and building in the lab" to "ready to deploy for clients." 🚀 I'm currently offering my services as an AI Automation Builder. My stack includes deep n8n workflow optimization, AI API integrations, and solid cloud infrastructure management to make sure your automations never sleep. If you need someone to connect your apps, build intelligent AI workflows, or just save you 10+ hours a week, my DMs are open. Who's building something exciting right now? Let's connect! 🌐
1 like • Mar 25
@Marcello Denver dm me
Mar 10 •
Workflow building is 10% logic and 90% "Why is this node failing?" 💀
We’ve all been there. You have the perfect architecture in your head, the canvas looks like a masterpiece, and then... one JSON error or a rate limit ruins your entire afternoon. Even after building hundreds of automated systems, I still run into "logic loops" that make me question my career choices for a solid hour. I’m curious—what is the single hardest thing you’ve faced in your journey building workflows? Is it: 🛑 Handling nested JSON data without losing your mind? 🔄 Managing complex error-handling and "wait" loops? 🏗️ Scaling the infrastructure (Azure/Docker/Self-hosting) so it doesn't crash? 🧠 Just getting the AI to follow instructions without "hallucinating"? Drop your "automation war stories" below. Let’s see who’s faced the biggest beast! 👇
1
0
1-9 of 9

Active 2h ago
Joined Dec 30, 2025
Powered by