Activity
Mon
Wed
Fri
Sun
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
What is this?
Less
More
Owned by Wes
Master Vibe Coding in our supportive developer community. Learn AI-assisted coding with fellow coders, from beginners to experts. Level up together!🚀
Memberships
New Society
430 members • $77/m
Agentic Labs
769 members • $7/m
AI Accelerator
18.4k members • Free
Startup Dawgs
82 members • Free
The Survey School
110 members • $199/month
Amplify Voice AI
155 members • $97/month
Skoolers
193.1k members • Free
AI Automation Society
348.9k members • Free
6 contributions to AI Automation Society

Feb 17 •
Sonnet 4.6 Released! — Benchmark Breakdown
Anthropic released Sonnet 4.6 today. Here's what changed and why it's worth paying attention to. The biggest jump: Novel problem-solving ARC-AGI-2 measures how well a model can reason through problems it hasn't seen before — generalization, not memorization. - Sonnet 4.5: 13.6% - Sonnet 4.6: 58.3% - Increase: +44.7 percentage points That's the largest single-generation improvement in the table by a wide margin. Agentic benchmarks The benchmarks most relevant to tool use and automation all improved significantly: - Agentic search (BrowseComp): 43.9% → 74.7% (+30.8pp) - Scaled tool use (MCP-Atlas): 43.8% → 61.3% (+17.5pp) - Agentic computer use: 61.4% → 72.5% (+11.1pp) - Terminal coding: 51.0% → 59.1% (+8.1pp) Sonnet 4.6 vs Opus 4.5 Worth noting — Sonnet 4.6 now outperforms Opus 4.5 on several benchmarks: - Novel problem-solving: 58.3% vs 37.6% - Agentic search: 74.7% vs 67.8% - Agentic computer use: 72.5% vs 66.3% Sonnet is the smaller, cheaper model tier — so this shifts the cost/performance equation for anyone building agentic workflows. What this means practically If you're building with tool use, MCP integrations, or multi-step AI workflows, the MCP-Atlas and BrowseComp improvements are the ones to watch. Models that reliably use tools and follow through on multi-step tasks open up a lot of what was previously too brittle to ship.

Feb 15 •
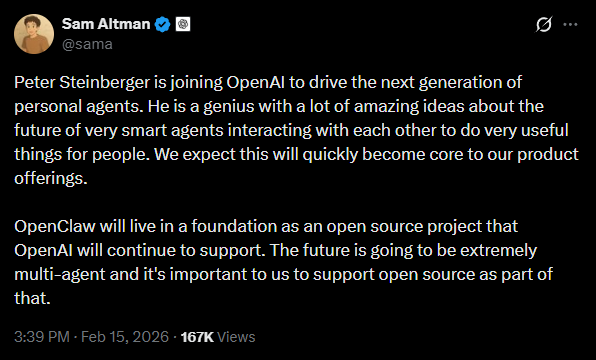
OpenClaw Creator Joins OpenAI
Sam Altman just announced it on X. What are your thoughts? Is this good or bad? https://x.com/sama/status/2023150230905159801?s=20
1 like • Feb 15
Here's Peter's announcement. https://steipete.me/posts/2026/openclaw
1 like • Feb 16
@Muskan Ahlawat I agree. He seems like such an individualist, though. I wonder how things will work out.
Aug '25 •
This is the best 😂
I never post memes, but this so perfectly nails vibe coding I had to https://youtube.com/shorts/v7AoKWTTe9k
Aug '25 •
Grok Code Fast 1 just dropped on OpenRouter - Don't Pay for It
This tutorial shows you how to access this brand-new coding model via RooCode Cloud absolutely free for the next 7 days.


💎
⭐
Jul '25 •
🚀New Video: Beginner’s Guide to Metadata: Make Your RAG Agents Smarter
In this video, I walk you through a no-code RAG (Retrieval-Augmented Generation) workflow I built using n8n. I’ll show you how I take YouTube video transcripts, store them in a Supabase vector database, and enrich them with metadata like video titles, URLs, and timestamps. This allows the RAG agent to tell me exactly where the retrieved answer came from — including which video, the link to that video, and even the moment in the video it pulled the data from. I also break down what metadata is, why it matters, and how it dramatically improves retrieval accuracy and context. If you’re building any kind of AI assistant or agent, this will be a foundational concept to understand — and I make it as simple and practical as possible. Google Sheet Template
2 likes • Jul '25
Is there a setup script for Supabase?
1-6 of 6

@wes-odom-5995
AI and automation enthusiast. Always learning.
Active 5d ago
Joined Feb 16, 2025
Powered by