Activity
Mon
Wed
Fri
Sun
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
What is this?
Less
More
Memberships
AI Automations by Jack
2.6k members • $77/month
6 contributions to Clief Notes

Mar 13 •
"I was backend lead at Manus. After building agents for 2 years, I stopped using function calling entirely. Here's what I use instead."
"I was a backend lead at Manus before the Meta acquisition. I've spent the last 2 years building AI agents — first at Manus, then on my own open-source agent runtime (Pinix) and agent (agent-clip). Along the way I came to a conclusion that surprised me: A single run(command="...") tool with Unix-style commands outperforms a catalog of typed function calls. Here's what I learned." https://www.reddit.com/r/LocalLLaMA/comments/1rrisqn/i_was_backend_lead_at_manus_after_building_agents NOT MY CONTENT
1 like • Mar 13
@Crae Säkkinen Skills do contain these fields: "Skill Metadata Fields The agent skills open standard supports several fields in the SKILL.md frontmatter. Two are required, and the rest are optional: - name (required) — Identifies your skill. Use lowercase letters, numbers, and hyphens only. Maximum 64 characters. Should match your directory name. - description (required) — Tells Claude when to use the skill. Maximum 1,024 characters. This is the most important field because Claude uses it for matching. - allowed-tools (optional) — Restricts which tools Claude can use when the skill is active. - model (optional) — Specifies which Claude model to use for the skill." This is from the Skill course Anthopic released: https://anthropic.skilljar.com/introduction-to-agent-skills/434526

Mar 13 •
AI platform design
Hello everyone I do present to the CEO a Ai platform design. Mind you i do not have any experience with AI so I have been do crazy amount of research and learning Python. My question to all of you is. What am i missing? Do you recommend other tools? This is to complicated? Tools to be used: Task Engine = LangGrapgh Tool Registry= developed internally Prompt builder = Jinja template
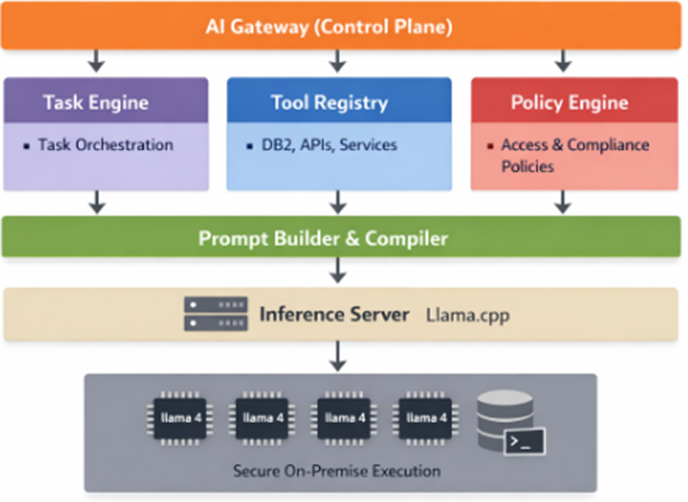
1 like • Mar 13
Jake’s file architecture:
Mar 12 •
How to improve output accuracy of analytical tasks with STAR Analysis
Thought this may be insightful to those running analytical tasks: "The car wash problem asks a simple question: “I want to wash my car. The car wash is 100 meters away. Should I walk or drive?” Every major LLM tested—Claude, GPT-4, Gemini— recommended walking. The correct answer is to drive, because the car itself must be at the car wash. We ran a variable isolation study to determine which prompt architectural layer resolves this failure. Six conditions were tested, 20 trials each, on Claude Sonnet 4.5. A bare prompt with no system instructions scored 0%. Adding a role definition alone also scored 0%. A STAR reasoning framework (Situation, Task, Action, Result) reached 85%. User profile injection with physical context—car model, location, parking status—reached only 30%. STAR combined with profile injection reached 95%. The full stack combining all layers scored 100%. The central finding is that structured reasoning outperformed direct context injection by a factor of 2.83×(Fisher’s exact test, p = 0.001). STAR forces the model to articulate the task goal before generating a conclusion, which surfaces the implicit physical constraint that context injection leaves buried. The addition of a sixth condition resolved a confound in the original five-condition design by isolating per-layer contributions: STAR accounts for +85pp, profile adds +10pp, and RAG provides the final +5pp to reach perfect reliability." Read the whole paper below...
1 like • Mar 12
@Shirsho Guha Always happy to help good Sir! I'm only using Claude on browser at the moment but I use it as a "## CONSTITUTIONAL LAYER" within the account level instructions: Exact instructions: --- ### Mandatory STAR Analysis Before producing any analysis, recommendation, or report, complete a STAR block: - **Situation:** current state, grounded in available data - **Task:** the actual goal (make the goal the subject, not the audit task) - **Action:** conditions that must be met for the goal to be achieved - **Result:** measurable success definition — stated as discrete, verifiable criteria where possible. A Result that cannot be checked against the output is not a Result. "The analysis is thorough" fails. "The recommendation identifies a specific tier placement and produces exact proposed wording ready to deploy" passes. Save the STAR block before proceeding. All subsequent reasoning is conditioned on the Task statement. If the Task statement names the wrong goal, the analysis will be wrong regardless of how much data is available. --- I've spend the last month or so building out the account architecture at the account and project level and its created a massive shift in the quality of output!
1 like • Mar 12
@Shirsho Guha I'm using it in the context of auditing accounts/analytical. Not for code. "RALPH loop", I cant comment on this as I have no idea what it is 😆 excuse my ignorance. My coding knowledge is thin.

🚀
⭐
Mar 2 •
Who's here? Drop your intro.
Tell us three things: 1. What you do (job, industry, student, career-changer, whatever) 2. What brought you to Clief Notes 3. One thing you're trying to figure out right now related to computing or AI I'll respond to every single one. And read each other's intros too because the person who's stuck on the same problem as you might already be in this thread. I'll go first I am Jake, I have been working in tech for 15 Years, building with Generative AI for 3 Years straight now! Excited to teach and learn! That's it. Simple, scannable, gives you data on who's joining and what they need, and keeps the feed clear for content that retains people past week one.
0 likes • Mar 12
@Yusik Hong Sucking at something is the first step to being good at it
6 likes • Mar 12
@Matthew Creamer Appreciate what you guys are building 🙏🏻 Thank you!
1-6 of 6
