Activity
Mon
Wed
Fri
Sun
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
What is this?
Less
More
Memberships
Clief Notes
27.5k members • Free
19 contributions to Clief Notes

3d •
Running everything locally
Has anyone here tried to make everything run locally similarly to how they do with Claude? While I enjoy Claude having a way to not be reliant on it (like with Ollama and Qwen/Gemma) might not be a bad idea. If you have done this what does your workflow look like? What was your process?

0 likes • 2d
I too have tried doing the local model route and it really excites me but I don't have enough hardware power. My system just can't hang with the lower-level models and then I don't get the higher-level results that I want from these cloud models so it's a no-go for me right now. I would totally love to get better at contextual memory for the models and start working more locally because I really see AI as, who knows, maybe it can't really sustain at this level forever. Certainly not for more than the next five years, like these super-powered AI agents might be going away unless quantum computing and cheaper pricing for hardware makes a return. Otherwise it's just too tough because we're all competing against these huge companies that are buying all the resources and the chips for their data centers to run AI. It's already a failed experiment in the sense that billions are just being burned right now. I wonder myself really what's the future state of AI? The current state's fantastic and the people that are paying for a cloud max subscription are really getting value for their money but then there is that trap of later being tied to one model or one company. Yeah you definitely have to diversify in this current environment
5d •
What is SWIM?
Today I'm launching an early access enrollment to a project I've been working on for the last 90 days, but really mapping out its internal workings for the last two years. It's been a long journey. It's a long story but it's finally starting to come to fruition and I wanted to share it as a win because my life story over the last three years has been tumultuous, to say the least. SWIM (Seamless Web Infrastructure for Merchants), is my earnest effort to want to really help merchants e-commerce from a place of dignity , because in today's market it feels like we're just all renting our space wherever we are. We've moved so far against what the internet was promising: to be more independent, less controlled, less monitored. That's what I'm looking for: merchant sovereignty. Join me on my mission to help merchants become sovereign. If you yourself sell online, we're starting with digital products. Hopefully in the next 60 days I'm not going to wait for it to be perfect. I'm not going to let fear overtake me or the false sense of security from the false sense of perfection. I don't even have my promotional video ready yet. It doesn't matter. I'm still going to roll with it. This is an ongoing process and it's part of what building in public really means. And I like this community and feel like this is the right place to just let it breathe. I've been trying to do this the right way - building while also organically marketing on Instagram, spending time on product market fit and really finding those users who are having these pain points, and there are a lot of them! But also building a company and taking seriously the structure and organization required in order for a company to scale, after all this is the new frontier for the solo dev entrepreneur. Anyway I've ranted enough. The link's below. Check it out. It does link to our documentation, which is still in the works. That's what I really love about this project: it was born more from the documentation and refining those ideas before any code was laid down. Even so, changes still had to be made throughout the process and they still do and it's a lot of fun. My focus again isn't becoming the next billionaire, although I don't doubt becoming one, but rather helping the merchant really succeed in such a large market that I see becoming more fraudulent and harder on the merchant every day. Our tagline is "Commerce flows through us. We are the infrastructure for your e-commerce experience. We're not just another store."
1 like • 5d
Posted about it on my blog too https://kuality.design/en/blog/why-im-building-swim-infrastructure-for-merchant-sovereignty
2 likes • 4d
It's a win building a SaaS platform as a solo developer using AI. The very tools that we're learning here to actually apply to something practical in our lives or to build something. It's posted under wins. I couldn't have gotten this far without LLMs. And the entire structure that it takes to build, maintain, and grow a tech company.
7d •
Adding ADRs at the end of my coding session has really been powerful.
I wrote an article about why you should use ADRs and what they are. It's a simple read, maybe like five minutes. https://kuality.design/en/blog/why-solo-developers-need-architectural-decision-records-adrs
0 likes • 7d
It's not just about how work sessions alone are tagged or wikilinked, front mattered, etc. It's specific decisions you took and why you made them that's what later comes back and bites you when you don't know why you made a decision because someone just looking at your code will not be able to glean that information
7d •
Token reduction maximization: a real stack that cut Claude costs by 30x
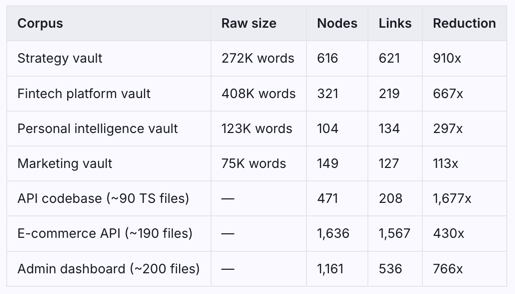
AgentsView says Mars processed $1,530 worth of tokens last month. The actual spend to date: $50. On a $100/month Claude Max subscription. Three tools. Here's how. Two numbers being measured: AgentsView reads local session token counts and multiplies by Anthropic's published API pricing. It doesn't know you're on Claude Max — a flat subscription, no per-token billing. So $1,530 is the real usage value: what it would cost on pay-per-token API. The $50 is what it actually cost. That gap has two causes: the subscription model, and a stack that compressed token usage before it ever hit the meter. Layer 1: RTK (Rust Token Killer) github.com/rtk-ai/rtk · brew install rtk RTK sits between your terminal and Claude's context and filters noise. git status on a 280-file repo normally dumps ~3,000 tokens of file listings into context. RTK trims that to ~200. Same information, 15x smaller, on every shell operation, without thinking about it. Layer 2: Graphify github.com/safishamsi/graphify · pip install graphifyy The heavy one. Graphify turns a codebase or document vault into a persistent knowledge graph — JSON and interactive HTML. Build it once, query it forever. Instead of Claude re-reading 10–15 files to answer a question, it traverses 3–5 nodes in a graph that already exists on disk. One session. 16 Obsidian vaults, 4 production codebases: [see attachment] 910x reduction means a corpus that used to cost 545,000 tokens to query now costs ~600. 🤯 It also finds connections that were never explicitly linked — concept clusters across files, architectural patterns that only become visible when everything is indexed at once. Layer 3: Markdown Guard hook This one doesn't save tokens. It keeps the agent safe. Vaults are full of external content: captured links, scraped docs, research notes pulled from anywhere. A poisoned .md file can silently redirect an agent mid-session — change what it does next, what it writes, what it deletes. When that agent has write access to your systems, that's not theoretical.
1 like • 7d
By the way, here's the link for agents for you. I realized I didn't add it. https://github.com/wesm/agentsview
1 like • 7d
I get it. Some of you don't use Claude. No problem. Roll with your own LLM. My hardware can't hang with local LLMs yet, at least the powerful ones, but it's definitely in my plans to not solely depend on Claude.

7d •
Seeking Architecture & Distribution Advice: 85+ Empathy-Driven Life Guides (Pro-Bono / Open Source)
I've spent the last few months building a library of 85+ practical guides for the hardest life situations people face - widowhood, losing a home to foreclosure, military-to-civilian transition, navigating executorship, first apartment, making friends as an adult. The kind of stuff people are Googling at 2am with no one to call. Each guide includes an integrated AI prompt. You fill in your situation, drop it into Claude or a model the person has access to, and it becomes a grounded companion that gets to know your particular circumstances - not a generic response, but one anchored to the specific guide you're working through. The goal is to give people a safe place to ask the questions they're too embarrassed or too isolated to ask another person (I've built-in safety sets and responses to ensure people don't give the AI sensitive information). I have zero interest in monetizing this. I really just want to find a way to help the most people without them having to pay for the assist (they have enough on their plate if they're using one of the guides). Here's where I'm stuck. The guides work. The delivery doesn't. Right now everything lives as .docx files. That's not a real product. I want to move toward a proper web app, then mobile. Three problems I don't have good answers to: Context loading. What's the cleanest approach to make sure the AI is reading the specific guide a user is looking at - not just running off a generic prompt? RAG? Direct document injection? Something else I'm not thinking of? API costs. Companion prompts at any real scale get expensive fast, especially for a free-to-user app. Are there AI for Good grant programs or API credit programs - Anthropic, Google, OpenAI - that fit a project like this? Architecture for handoff. As I'm building this to give it away, what stack gives a small non-profit with minimal technical capacity the best shot at maintaining it long-term? Longer shot, but genuinely asking: does anyone know an organization or NGO that's actively looking for something like this? A fully built content library with AI companion infrastructure, no strings attached.
1 like • 7d
Here's the link to that other discussion on token reduction, which I think will help you if you're going to be doing heavy research. https://www.skool.com/quantum-quill-lyceum-1116/token-reduction-maximization-a-real-stack-that-cut-claude-costs-by-30x?p=0aeb0485
1 like • 7d
Nice! I've heard great things about Notebook LM. I haven't personally used it, but I understand what it does. I built something outside of that because I don't want Google to have access to my information, but it's a totally valid, great solution. Best of luck. If you have any questions, feel free to reach out.
1-10 of 19

Active 8h ago
Joined Apr 11, 2026
ENTJ
Montevideo, Uruguay
Powered by