Activity
Mon
Wed
Fri
Sun
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
What is this?
Less
More
Owned by Dev
𝗠𝗮𝘀𝘁𝗲𝗿 𝟱 𝘁𝗶𝗺𝗲𝗹𝗲𝘀𝘀 𝘀𝗸𝗶𝗹𝗹𝘀 𝘁𝗼: Fill Pipeline → Get Shows → Close → Onboard Fast → Renewals for Years 🚀 💫
Memberships
Contractor Marketing Community
1.5k members • Free
Freedom Academy
405 members • Free
The Ai Agency - Free Resources
1.4k members • Free
Q's Mastermind
5.8k members • Free
Web Agency Accelerator (FREE)
15k members • Free
Stone Scaling GHL-($0-10k/mo)
1.5k members • $700
HighLevel House
1k members • $122/m
Smart AI Operators
2.7k members • Free
Lead Gen Insiders 🧲
1.8k members • $1,497
1 contribution to Ai Titus

Oct '25 •
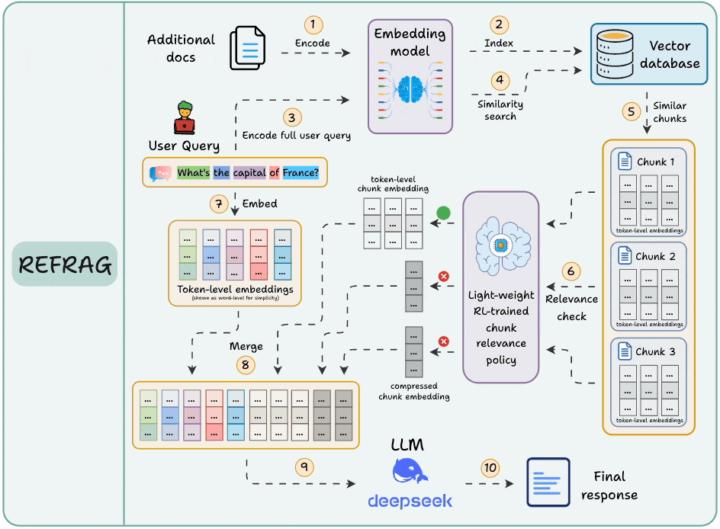
You're Burning Money with RAG, REFRAG instead! Meta Just Fixed It (30x Faster, 16x More Context)
If you built a RAG system, you made a crucial mistake. Not your fault—everyone did. You're feeding your LLM massive amounts of text it doesn't need. Paying to process tokens that don't matter. Waiting for responses while the model reads through garbage. And getting slower, more expensive results than necessary. Meta AI just released research that proves something most people building RAG systems don't realize: most of what you retrieve never actually helps the LLM generate better answers. You're retrieving 10 chunks. Maybe 2 are useful. The other 8? Dead weight. But your LLM is processing all of them. Reading every word. Burning through your token budget. Adding latency to every response. This is the hidden cost of RAG that nobody talks about. And it's getting worse as you scale. But here's what just changed. Meta's new method REFRAG doesn't just retrieve better. It fundamentally rethinks what information actually reaches the LLM. The results? 30.85x faster time-to-first-token. 16x larger context windows. Uses 2 to 4 times fewer tokens. Zero accuracy loss. Let me show you exactly what's happening and how to implement this approach right now. The Problem With Every RAG System You've Built Traditional RAG works like this. Query comes in. You encode it into a vector. Fetch the most similar chunks from your vector database. Dump everything into the LLM's context. Sounds good. Works okay. But it's brutally inefficient. Think about what's actually happening. You retrieve 10 document chunks because they're similar to the query. But similar doesn't mean useful. Some chunks are redundant—saying the same thing different ways. Some are tangentially related but don't answer the question. Some are just noise. But your LLM reads all of it. Every single token. It's like making someone read 10 articles when only 2 are relevant, and you're paying by the word. The costs compound fast. More tokens means higher API bills. Longer processing time means slower responses. Bigger context means you hit limits faster. And none of it improves your answer quality.

1 like • Oct '25
@Titus Blair this one 😊
1 like • Oct '25
@Titus Blair i'll be waiting cuz you got the sauce LOL 💥👊 (fist bump) lmk the name of the newsletter when you get a chance 🤙
1-1 of 1

@dev-tyler-9992
@illiniDev | Web Design & AI Marketing Systems 🤩
Active 11h ago
Joined Oct 3, 2025
NYC