Activity
Mon
Wed
Fri
Sun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
What is this?
Less
More
Memberships
42 contributions to AI Bits and Pieces

🔥
4d •
📊 AI in Real Life: My Personal AI Health Dashboard
One of the most practical AI systems I use every single day has nothing to do with coding, agents, or automation workflows. It’s my personal nutrition and activity tracker and daily dashboard. I log the food. I log the activity. ChatGPT does the rest. Every day: I log food, activity, bodyweight, and water as it is happening. ChatGPT estimates activity burn, subtracts it from my food intake, and then factors in my BMR to show whether the day is trending toward maintenance, fat loss, or an aggressive calorie deficit. Then, at the end of the day, it turns the raw inputs into a dashboard showing calories, macros, activity burn, net calories, net + BMR, protein density, protein per pound, fiber tier, fat-source patterns, etc. Because I follow a higher-protein diet, I also created a metric I call Protein Density: Protein grams ÷ total calories consumed (by snack, meal, day). The metric is useful because I can monitor food quality as I eat throughout the day, not just total calories. A good Protein Density score is: 0.10 or higher That generally means the day is optimized for muscle preservation and fat-loss efficiency. A lower score around: 0.05 That usually signals a less efficient nutrition day where calories are climbing faster than protein intake. For example: Chicken Breast (100g cooked, skinless): - ~165 calories - ~31g protein 31 ÷ 165 = 0.19 Protein Density Compare that to potato chips: Potato Chips (100g): - ~536 calories - ~7g protein 7 ÷ 536 = 0.01 Protein Density Both are food. But one is highly protein-efficient, while the other is primarily calorie-dense with minimal protein value. That simple ratio gives me immediate feedback on whether my meals are supporting my goals before the day is even over. The key for me is context. A 1,600-calorie day means one thing if I barely moved. It means something very different after 16,000 steps, hills, heat, and a high-output activity day. That is where AI becomes useful. Not just tracking data.
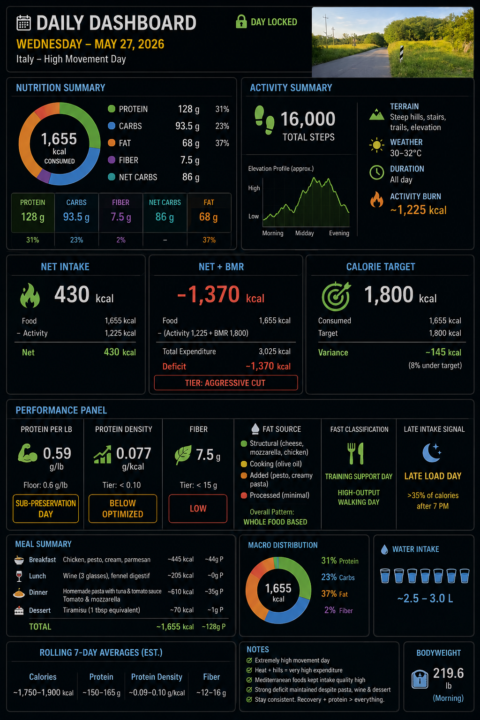

1 like • 4d
@Michael Wacht this is cool! Do you use an app to log all this stuff?
🔥
10d •
AI Week Update: The Real Problem Behind Artificial Intelligence - Water. 💧🤖
Everyone is talking about AI productivity. Faster coding. Smarter agents. Digital labor. Autonomous systems. But underneath the excitement, another conversation is quietly emerging: Water. 💧 Not metaphorically. Actual water. We keep drawing analogies between AI and humans. How we will work with it. How we will manage it. How it may change our relationship with labor, creativity, and knowledge. But I never fully connected one basic fact: Like humans, AI needs water to survive. Not emotionally. Not philosophically. Physically. Data centers need water for cooling. AI infrastructure needs water to operate. And as AI grows, that demand grows with it. No false pretenses here. In the United States especially, these resources are often taken for granted. There is an assumption that water, energy, and infrastructure will simply continue to be available in the future because they always have been. But the numbers are becoming too large to ignore. Some estimates now project AI-related infrastructure consuming hundreds of billions of liters of water annually. Large data centers can consume millions of gallons of water per day for cooling. Researchers have also estimated that training GPT-3 alone required roughly 700,000 liters of freshwater. At AI Week, this issue was barely discussed compared to compute, chips, models, or agents. The industry talks constantly about scaling intelligence, scaling infrastructure, and scaling automation. Sure, we occasionally hear about a city council meeting where citizens are protesting a proposed data center. But rarely do we seriously discuss the scaling of the physical resources underneath it all. Electricity. Cooling. Land. And water. That was my biggest realization. AI is not just software anymore. It is industrial infrastructure. And industrial infrastructure has physical consequences. The next major AI race may not simply be about who has the best model. It may become who has the energy, who has the cooling capacity, who has access to water, and who can sustain all of it economically and politically.

2 likes • 9d
@Michael Wacht yeah that is something that is rarely discussed. But it’s a major concern if things keep going the way they have been.

🔥
12d •
Website?
Hey everyone 👏🏻 I'm working to improve my website , here's the results how it's looking now? Let me know how it's? And anything I can improve??

2 likes • 12d
@Muskan Ahlawat good start! How did you make it?
🔥
15d •
🇮🇹 Off to Milan, Italy for Europe’s Largest AI Conference
Over the next several days, I’ll be attending an AI conference in Milan, Italy — spending time listening, learning, testing ideas, and having conversations with people building at the edge of where this technology is heading. ✈️ I’ll still work to maintain content and keep things moving inside AI Bits & Pieces, but this trip is also an important reminder of something: Sometimes the highest-value thing you can do is to stop, observe, listen carefully, and consider other perspectives. The AI space is moving fast. ⚡ New tools. ⚡ New workflows. ⚡ New business models. ⚡ New assumptions being challenged almost weekly. And while online content is useful, there’s still tremendous value in getting into rooms with operators, builders, founders, developers, and enterprise leaders to hear what is actually working in the real world. 🎯 My goal is simple: ✅ Come back with insights worth sharing. ❌ Not hype. ❌ Not recycled headlines. ❌ Not “AI influencer” noise. Real observations. Real workflows. Real opportunities. Real AI lessons. 🙏 Appreciate everyone here who continues to contribute, ask questions, experiment, and help make this community valuable. Now it’s time for me to go learn a few new things. 🇮🇹
1 like • 14d
@Michael Wacht enjoy! Looking forward to hearing all about it!
🔥
15d •
Better Late Than Never Apple?!?
Apple's new Siri chatbot app to feature auto-deleting chats Bloomberg’s Mark Gurman reports the standalone Siri app, set to rival ChatGPT and Claude, will let users control how long AI conversations are stored. Apple is building a privacy-focused chat retention system into its upcoming standalone Siri app, giving users control over how long their AI conversations are stored — a feature that distinguishes it from competing chatbots like ChatGPT, Gemini, and Claude. Standalone App Marks a Strategic Shift The standalone Siri app, codenamed “Campo,” represents a reversal from Apple’s earlier plans. Gurman had previously reported that Apple did not intend to build a dedicated Siri app, preferring to embed the assistant across its ecosystem. The rising popularity of chatbot apps from OpenAI, Anthropic, and Google pushed Apple to reconsider. Read entire article: https://www.perplexity.ai/page/apple-s-new-siri-chatbot-app-t-C_meQ0ttSguXtNghs6ZvIg
3 likes • 15d
@Michael Wacht hopefully they will release it at some point. They have been promising Siri 2.0 for a few years now.
1-10 of 42
Active 24m ago
Joined Sep 18, 2025
Puyallup, WA
Powered by