Activity
Mon
Wed
Fri
Sun
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
What is this?
Less
More
Memberships
Rewilding the Soul
2.2k members • Free
Crypto Cash Flow
149 members • Free
Faceless Freedom
45 members • Free
Agent Zero
2.6k members • Free
28 contributions to Agent Zero

Apr 2 •
Preferred Browser for Agent Zero
Hey everyone - with the new plugin system what is your experience and preferred browser when working with Agent Zero? As I understand, Playwright is the default browser and we have CamoFox as a plugin. Has anyone tried other browsers? What is your experience?
0
0
Apr 1 •
Local LLM Performance vs Frontier Models
Just thought I would share how I compare open source LLMs to the big proprietary models. I prefer using local LLMs for Agent Zero - for privacy, speed, and unlimited use. However, there are some pros and cons - and choosing the best model for Agent0 can be challenging when there are so many models to choose from and new ones being released practically every week. This is where https://artificialanalysis.ai/ comes in very handy. I use this site to compare the intelligence and speed of models against each other. It also has a special page for coding performance. Hope you all find this useful.
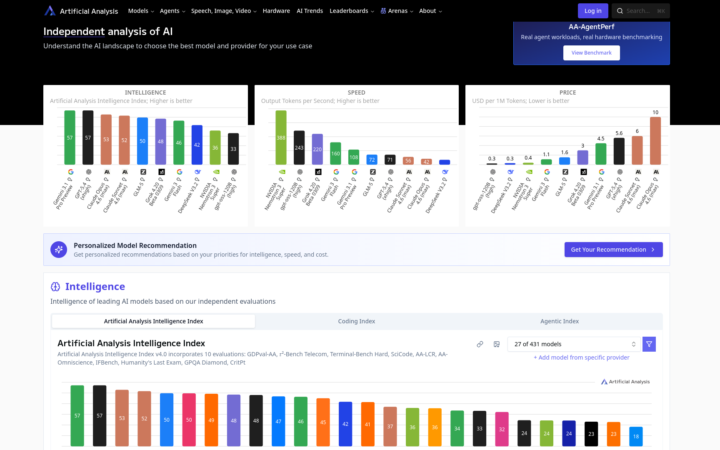
0 likes • Apr 2
Forgot to mention - there are a lot of filters so you can distinguish between proprietary models and Local LLMs. You can also add custom LLM to the chart from a drop-down list, this gives you the chance to compare a specific LLM's performance against top models for intelligence, speed, and coding.

Apr 1 •
Seeking a new friend
Hi everyone! Currently I am looking for a someone who can collaborate with me for the long term. This is long term friendship. I would love to connect with you, whatsapp: +81 80 1455 6262 If you are interested in, please give me Dm or message on whatsapp
0 likes • Apr 1
I see you are into web3, crypto, and full stack development. I do a little of that myself. Currently I am building an automated social media system where the agent creates bulk social accounts, warms them up, then schedules content posts. This would free me up to focus on securing good products or services - eventually making passive income once the whole system is running. Is this the sort of thing you are into?
0 likes • Apr 1
@Morimura Din That depends. First, tell me - what is your favorite Anime series?

Mar 20 •
Connecting AgentZero to Signal
Hi guys, I'm just strating with A0 and I wanted to know if there's a way to connected it to the signal cli. Even if it's not a native way inside of agent zero
1 like • Apr 1
Yes, this is possible. I haven't done it yet myself. I was working on this and then the new version 1.6 came out. With the new plugin system there may be a plugin for signal. I have yet to install the latest version. Anyways, yes it is possible to use signal-cli

Mar 25 •
Looking for American or European Collaborators for our Team
Hi, I’m an AI engineer from Japan working on expanding into the U.S. market. I really enjoy the technical and development side of projects, but I’d love to connect with someone from the U.S. or Europe who is confident in English communication and interested in collaborating on client-facing conversations to earn extra income. I’m not just looking for a one-time arrangement, but for someone I can build a good working relationship with over time. If that sounds like something you’d be open to, feel free to message me. My telegram id is @phil1pxx, and my personal email is [email protected]
0 likes • Apr 1
Can you elaborate on the types of projects you create? What market and segment are you in?
1-10 of 28
@daniel-p-4970
Certified IT professional and Linux user. Investigative researcher.
Active 18d ago
Joined Mar 2, 2026
USA
Powered by