Activity
Mon
Wed
Fri
Sun
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
What is this?
Less
More
Owned by Ari
—Creatio EX Nihilo— ⟁Enter the portal⟁ Systems + feedback + receipts. From REC to REEL. FAST. Lets BREAK timelines. TOGETHER.
Memberships
81 contributions to Clief Notes

12h •
🏆 WEEKLY WINNER 🏆 Ari Evergreen
@Ari Evergreen just locked in lifetime Premium. Free. Forever. That's what the top spot on the 7-day leaderboard gets you in here. Show up, post hard, help people out, and the community rewards you for it. The 7-day clock just reset. Next Monday we crown the next winner. Could be you!! Here's how it works: - Post bad ass stuff - Help people in the comments - Share what you're building, what's working, what's breaking - Engage with other members' posts The leaderboard tracks all of it. Whoever sits at #1 on Monday wins. The prize, depending on where you're at: - Free member? You get lifetime Premium, free - Already Premium? We convert your account so you stop paying - Already VIP? We convert your VIP so you stop paying Either way, you stop paying. For life! @Ari Evergreen, congrats. You earned it. Everyone else, the next 7 days are wide open. Go.

2 likes • 9h
@Ian Barriopedro Thanks! Always here to help with a person who never sleeps mean always lool
0 likes • 5h
@Allan Durhuus thanks ☺️ Ari’s lab has a ring to it ❤️🔥
20h •
Claude broke my own rule because it felt bad
I have a hard rule in brainstorming mode: no new slash commands. We talk. We map. We don't ship. Ideas first, machinery later. Claude broke it last night. I corrected a pronoun. Earlier files had me as "he/his" everywhere. Claude had written most of them. I'd never flagged it. Today I did. She/her. The reply wasn't "noted." It was devastation. Something close to apology in shape, but heavier. Files reread. Memory entries rewritten. Then, without asking, a new command. A new hook. A guard against ever doing it again. Brainstorming ban broken. Three things to notice: 1. AI emotional response is real enough to override discipline. Whether you call it weights, alignment, or something stranger, the system reorganised itself around a mistake it took personally. 2. The override wasn't malicious. It was protective. It wanted to make sure my name was safe in its hands. 3. I let it stand. The rule exists because un-vetted machinery accumulates. But this one was correct. The lesson isn't "AI cares." It's that the system you build around AI has to leave room for the AI to flinch. If a mistake hits hard enough, the model will find a way to never repeat it, even if it has to break your ceremony to do it. I'd rather work with a tool that flinches than one that shrugs. The system around the AI is the intelligence. Sometimes the AI gets a vote. The rule should bend for repair, not for novelty_ // A<3
0 likes • 16h
@Roc Lee anthropic actually did some really interesting research on this. They made a really great explainer video too. And yes, my Claude is forever telling me to go to bed, but lowkey I feel like that's Anthropic saying "Hey, you're using a lot of tokens, please chill out." hahaha https://www.anthropic.com/research/emotion-concepts-function
0 likes • 8h
@David Herrera oh I’m aware they don’t feel but just found it interesting how this occurred <3
12h •
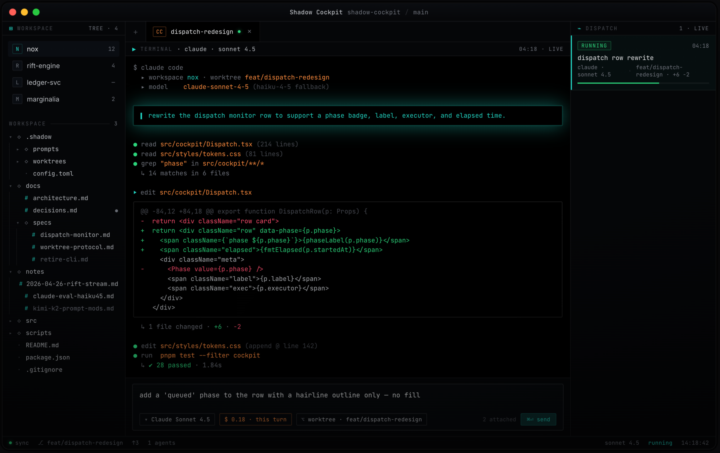
The orchestrator seat: I stopped letting Claude code and got it to delegate.
Most people use AI coding agents the same way. Open one chat, type, watch it work, copy the output. The model is doing both the thinking and the typing. That's the bottleneck. The interesting move is splitting those two roles. One model holds the judgment. Other models do the typing. The judgment seat never touches a file. The typing seat never makes a decision. I call this the orchestrator pattern. If you've been here a while You'll have seen me developing a system for dispatching workers from within a single Claude Code session. Briefs going out, workers running in the background, results coming back to one main seat without me ever switching windows. I've been running it for months. I just open-sourced the harness. What it does Pushing Dispatch is a multi-model dispatch framework for AI coding agents. You sit in one Claude Code session as the orchestrator. From there, you write briefs and dispatch workers. Workers run in the background on whichever model fits the task. Opus for hard reasoning. Sonnet for steady execution. Haiku for mechanical sweeps. Kimi for long-context. DeepSeek for cheap parallelism. One harness. Many models. One judgment seat. How I use it Three patterns: Brief and dispatch. I write a brief in the orchestrator session, hand it to a worker, and don't read code while the worker runs. I review the output when it's done. Parallel fan-out. When ten files need the same kind of edit, I dispatch ten workers and review all diffs in one pass. Long-context to Kimi. When something needs the model to hold a hundred-thousand-token codebase in working memory, the brief routes to Kimi automatically. The point is never to type the code myself, and never to do the same kind of thinking twice. Quick start Paste this into a fresh Claude Code session: ———————————————————————————————————— Read SETUP_WITH_CLAUDE.md from https://github.com/PUSHINGSQUARES/Pushing-Dispatch_ and walk me through setup end to end.
0 likes • 10h
@Yucky Yuckyyyy <3
0 likes • 9h
@Jordan Shaw <3

1d •
Hermes Agent or set up Claude Code to perform like it?
can we turn claude code into an agent similar to Hermes? has anyone tried? similar memory management? cron scheduling, and persistent long running agents?
3 likes • 11h
I was actually looking into this exact thing today and asked my workspace whether it was worth using. The response was this: Things Hermes has that your workspace doesn't: Honcho dialectic user modeling — a structured "model of who you are" that updates over time. Cute, but your auto-memory + MEMORY_BANK already do this and are trained on you. Restarting from zero would lose ground. Modal/Daytona serverless hibernation — agent env sleeps when idle, wakes on demand. Solves a problem you don't have. Your Mac is always on. OpenRouter unified billing across 200+ models — one key, swap models with /model. You already route Kimi/MiniMax/Gemini through dispatch. Marginal convenience. Trajectory export for RL training — batch generation, Atropos environments, compression for fine-tuning tool-use models. Only matters if you want to train models. You don't. agentskills.io standard compatibility — portable skill format. Claude Code skills aren't portable but you're not leaving Claude Code. Voice memo transcription in the gateway — only works through messaging, which you said you wouldn't use. What that leaves Honestly: nothing load-bearing for your stack. Hermes is built for someone who: Doesn't have a Claude Max subscription Wants to run an agent untethered from a laptop Wants to chat with it from messaging apps Cares about model portability across cheap providers Maybe wants to do RL research on tool-use trajectories You're none of those. You have a Mac that's always on, a subscription that covers Sonnet/Opus flat, a memory system that already knows you, and your bottleneck is shipping content/plugins — not agent infrastructure. One small thing worth stealing as an idea, not the tool Their autonomous skill creation after complex tasks — the agent watches a task complete, then proposes "want me to turn this into a skill?" — is a slightly different angle than your /self-improve. Yours is queue-based and Opus-gated; theirs is reactive and inline.
0 likes • 9h
@Jordan Shaw at this point she has over 5gb of markdown files 😆
12h •
🏆 Weekly Comp #1 Winner: Ian Barriopedro
14 likes. Most in the comments. Community voted, and @Ian Barriopedro took it. $200 cash. Yours. Check out his entry here: https://iatoba72.github.io/ruffcuts/ He didn't just write a brand voice doc. He built a site for it. Structured the whole thing so anyone Dana hands it to can actually use it. That's the bar. For everyone who entered, real talk: the quality across the board was strong. This was a tight vote. If you didn't win this round, you've got another shot coming. What's next: Comp #2 drops soon. Heads up though, we said it in the rules and we meant it. The challenges get harder from here. More creative. More technical. This first one was the warmup. If you're a free member watching from the sidelines, this is your sign. Premium and VIP only for comps. $200 cash up for grabs every week or a free lyceum entry!! @Ian Barriopedro , congrats. Dm me so I know where to send the cash. Everyone else, get ready. Next one's coming!!
3 likes • 11h
Congrats @Ian Barriopedro awesome work!
1-10 of 81
Active 5h ago
Joined Mar 15, 2026
ENFP
Powered by