
Write something

Dec '25 •
Why your data pipeline feels busy but still doesn’t help decisions
I see this a lot in teams working with data + AI. Pipelines are busy. Events flowing. Running analysis and nurturing. Dashboards updating. Yet when a real decision needs to be made, people still ask: “Can someone look into this?” That’s a signal something’s off. A busy pipeline doesn’t mean a useful pipeline. Here’s the common issue, in simple terms: Most pipelines are built to move data, not to support decisions. They focus on: • ingesting everything • transforming everything • storing everything But they forget to ask one basic question early: 👉 What decision is this data supposed to help us make? When that’s unclear, pipelines become noisy. A healthier pipeline looks like this: Decision first Example: “Do we intervene when user churn risk increases?” Minimal signals Only ingest data that actually affects that decision(not everything you can track). Clear thresholds At what point should the system alert, act, or stay quiet? Simple output Not a dashboard. A recommendation, alert, or action. This is where AI actually helps —by filtering noise, summarizing context, and pointing to what matters now. Busy pipelines move data fast. Good pipelines move understanding fast. Data alchemy isn’t about making pipelines bigger. It's about making them calmer, clearer, and decision-ready.

Dec '25 •
Power BI Modeling MCP Server: Revolutionize Your Data Analysis
30 minutes instead of 3 hours. Yes, you read that right. I discovered Power BI Modelling MCP Server and it completely changed how I analyze data. Context: Analyzing the downloads data of my ebook "The AI & Data Alphabet 2025" ➤ Before: 2-3h manual cleaning + DAX measures creation ➤ After: 30 minutes flat What changed: ✓ Automated data cleaning ✓ Intelligently generated DAX measures ✓ Optimized relational model effortlessly Result? I can finally focus on : → Design → Visualization → The story my data tells No more time wasted on repetitive tasks. AI handles the technical work, I focus on insights. Need to analyze your Excel or Google Sheets data to save precious time? Comment "MCP" or contact me directly here:[email protected] See the demo here : https://www.linkedin.com/posts/sikati-yves-joseph-039215330_powerbi-mcp-dataanalytics-activity-7405983959383293952-FufT?utm_source=share&utm_medium=member_desktop&rcm=ACoAAFNTSu0BMmAIuDsPU-opNQXNfJE12Ba-Vg4 and follow me on on my socila media availble here : https://bit.ly/m/yvesvirtuel #share #entrepreneur #AI #africa #education
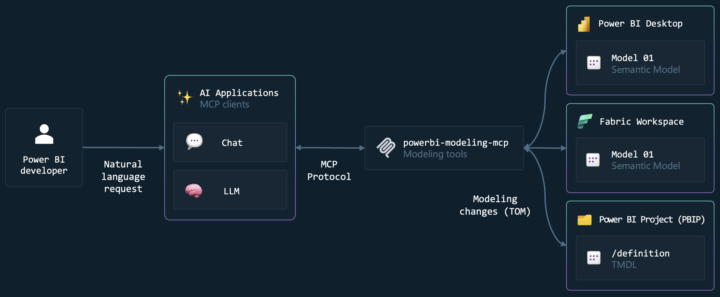
Dec '25 •
🚨 Good news for fans of Ollama and open-source LLMs!
👉 Ollama has just launched its Cloud version🚀 📚 To access the documentation, just click [https://www.notion.so/Yves-Virtuel-IA-Data-Automatisation-2b072d336c2e81d4842cf76cc24cf403?source=copy_link#2d872d336c2e80229512e86b5d6862f2]. 🔧 For integration with n8n or Python, feel free to reach out to me here if you run into any issues. 📲 I’ve also launched my WhatsApp channel check it out via this link: [https://whatsapp.com/channel/0029Vb6fWEdCcW4hXGiJyR3b]

Dec '25 •
The missing layer in most data stacks: decision memory
Most data stacks are excellent at answering: “What happened?” Very few are good at remembering: “Why did we decide this?” That’s a massive blind spot. Every meaningful decision creates context: • assumptions • confidence level • alternatives considered• time pressure And then… it disappears. High-maturity data systems include decision memory. Here’s what that looks like: 1️⃣ Decision Logging Not just outcomes, but: • what signals triggered action • what thresholds were crossed • who (or what) made the call 2️⃣ Assumption Tracking Every decision is tied to assumptions. When assumptions change, the system flags it. 3️⃣ Outcome Attribution Did the decision Help ?Hurt? Have no effect? Most teams track results but not causality. 4️⃣ Feedback into Models Signals that consistently mislead get down-weighted. Reliable ones gain influence. This turns hindsight into learning. 5️⃣ Retrieval at Decision Time When a similar situation appears, the system surfaces: • past decisions • outcomes • lessons This is institutional memory — automated. Data alchemy isn’t about storing facts. It’s about remembering judgment. The future belongs to systems that don’t just analyze the past, but learn from their own decisions.
Dec '25 •
Data Drift & Why Models “Feel Wrong” Over Time
Ever noticed this? Your data model works well for a few months. Predictions look right. Insights feel sharp. Then slowly… things feel off. Nothing is technically broken. But decisions based on the data don’t hit like they used to. This usually isn’t a tooling issue. It’s data drift. Here’s what’s actually happening: • User behavior changes • Market conditions shift • Internal processes evolve • Edge cases become the norm But the model is still thinking in the old reality. Most teams only monitor: – accuracy – performance – latency Very few monitor relevance. Good data teams do one simple thing differently: They regularly ask “Does this data still represent how the business works today?” Practical examples: • Last quarter’s “high-value user” definition no longer applies • A metric that mattered before is now just noise • Old patterns are being over-trusted AI doesn’t fail loudly. It drifts quietly. Data Alchemy isn’t just about building models —it’s about knowing when reality has changed and your data hasn’t caught up yet. Sometimes the smartest move isn’t improving the model. It’s redefining what “signal” means right now.
1
0
1-30 of 2,619

skool.com/data-alchemy-9173
Your Community to Master the Fundamentals of Working with Data and AI — by Datalumina®
Leaderboard (30-day)
1
+68
2
+12
3

+11
4

+11
5

+10
Powered by