
Write something

Apr 14 •
🎁 New Cheat Sheet Drop: How to Use Less Token
Tokens = Money. Most people burn 3–5× more than they need on Claude without realizing it. I put together a 2-page cheat sheet covering everything I wish someone had handed me when I started: Page 1 — the essentials - Pricing per 1M tokens (Opus, Sonnet, Haiku) - The Savings Stack (these multiply, not add — 80–95% cuts are normal) - The 5 core tactics: right-sizing the model, prompt caching, shorter prompts, output control, context trimming - Common token wasters to stop doing today Page 2 — the deep dive - Claude Code in the terminal: slash commands, CLI flags, how to slim your CLAUDE.md - Prompt caching full Python example (what to cache, what the response tells you) - Prefill tricks that kill the "Sure, here you go..." preamble - Model decision tree (when Haiku, Sonnet, Opus each) - Real-world recipes: cheap classifier, long-doc Q&A, cost-capped agent loops, batch evals - A pre-ship checklist you can run through before deploying 📎 Attached: Token_Saving_Cheat_Sheet Drop a comment with the one tip that surprised you most, or your own token-saving trick. Vincent
Mar 26 •
Claude Cheat Sheet (March 2026)
We just hit 50 members. so I made something for all of you😄. A one-page Claude cheat sheet covering models, pricing, prompting patterns, Claude Code commands, and API basics. Stuff I reference daily. --> PDF attached, keep it handy and share it with anyone who uses Claude. Things change fast with Claude so I'll keep this updated overtime. If you spot anything off or want a deeper one on a specific topic (Claude Code, API, prompting), let me know in the comments.
Apr 6 •
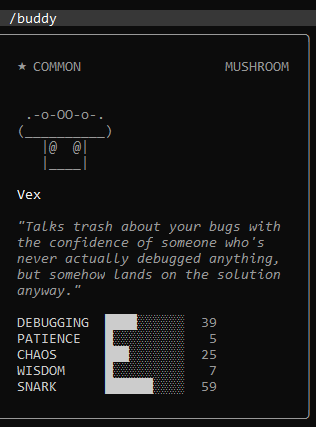
Has anyone tried the /buddy Claude Code Easter egg in the terminal ?
Hi ! For those having a break, wish you a great relaxing time. If you have been using the Claude Code terminal, you might want to check out this Easter egg that was recently discovered. It turns out the Anthropic developers hid a tiny virtual pet in the code. It is basically a terminal Tamagotchi that just hangs out quietly while you work. Just as a heads up, since this is a hidden Easter egg specifically for the command line tool, it will not work in the standard Claude web chat. To trigger it, all you have to do is type /buddy into your session. Here is what happens when you do: - It picks a species: The tool spawns a little ASCII art animal. There are 18 different species it can pick from, like a cat, a duck, or even a capybara. - It rolls for rarity: Each pet has a random rarity level ranging from common to legendary. If you get an uncommon one or better, your buddy actually wears a little hat. It could be a beanie, a wizard hat, or even a tiny duck sitting on its head. - It keeps you company: It does not mess with your code or your prompts at all. It just sits there and has some hidden background stats that shift around based on your activity during the session. It is a really geeky Easter egg but a nice touch to make working in the terminal a bit more chill. I got this one below in mine. If you get a rare one with a cool hat, drop a screenshot in the comments. I am curious to see what everyone rolls.
1-3 of 3
powered by

skool.com/claude-learning-skool-9159
Master Claude AI from first prompt to production. 30 video modules, 4 levels, 7 learning paths.
Suggested communities
Powered by