
Write something
Pinned

May 8 •
Big announcement for everyone in my free Skool community.
I’ve decided to open access to my premium Skool community for only $290/year. This is not just another community with random posts. Inside, you get access to a lot of automation workflows, AI tools, tutorials, ideas, and real systems that can help you save time, create content faster, automate your business, and learn how to use tools like n8n, Make, AI agents, ChatGPT, Claude and more. You also get support when you need help understanding or implementing the automations. The reason I’m posting this here is simple: many people stay in the free community, but they don’t take the next step. The premium community is where I share the deeper workflows, better resources, and more practical automation systems. The price is now only $290 for one full year. I don’t know how long I will keep it at this price, because I’m adding more content and more automations all the time. As the value grows, the price will increase. So if you were thinking about joining, this is probably the best moment. Join here:https://www.skool.com/automation-tribe I recommend you take action now, because this offer may not stay available for long.
Pinned
May 5 •
I’m tired of spending 2 hours editing a 30-minute video...
Hey Tribe, Let’s be honest: Recording a video is fun. Editing it is painful. I was spending way too much time hunting for "umms," "ahhs," and long silences in my timeline. So, I decided to build a solution that allows me to edit video just like I’m editing a Google Doc. It’s called Tribe Video Cleaner, and I’m giving it to you today for free. What it does: - Transcribes your video using OpenAI Whisper or ElevenLabs. - Auto-detects filler words, silences, and double takes. - Cleans your video in one click—no timeline scrubbing required. I’ve put together a full walkthrough on YouTube showing exactly how I built it and how you can use it to save hours this week. 📺 Watch the Walkthrough: https://youtu.be/u_kfo-XVc_Y If you’re a developer or want to run it locally, you can grab the code on GitHub below. (If this helps you, please leave a ⭐ on the repo—it helps me know I should keep building tools like this!) 🚀 Get the Tool on GitHub: https://github.com/grafup/Tribe-Video-Cleaner Stop editing. Start creating.
Pinned
Apr 22 •
I’m Rebuilding My Website with AI (Full Series Started)
I just started a new series where I rebuild my website using AI from scratch. This is not a basic tutorial. I’m turning automation-tribe.com into a real business, step by step: - Design with Claude Design - Build with Claude Code - Deploy with GitHub + Vercel - Add content automatically - Market it - And monetize it Here is Episode 1: https://youtu.be/Z6VF_fZUiVw If you want access to the exact prompts I use, they are available in my paid Skool community: https://www.skool.com/automation-tribe This series will show everything from start to finish.
21h •
Gemini is now in Chrome for everyone
Gemini just landed in the Chrome sidebar for everyone, not only paid AI users. You can now summarize any page, ask questions about what you are reading, or draft an email without leaving the tab. It also pulls context from the page itself, so prompts are not starting from zero. For anyone building on top of AI workflows, this is a major distribution event. Google just put an assistant in front of roughly three billion Chrome users by default, and you do not need an account to use it.

19h •
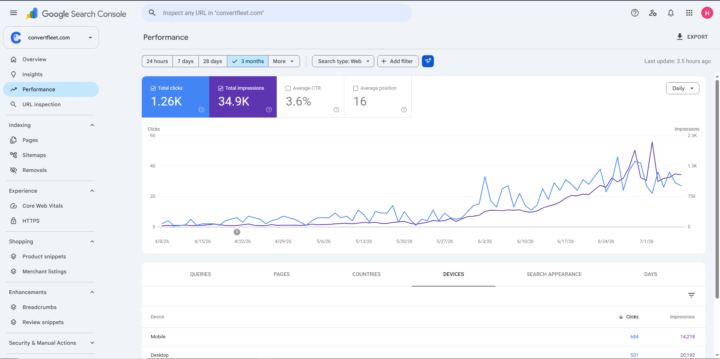
From 0 → 1.2K clicks and 35K impressions in 3 months — built almost entirely by my AI SEO agent, "Hermes." 🚀
Three months ago, ConvertFleet was invisible on Google. Today the Search Console dashboard tells a different story: 📈 1.26K total clicks 👀 34.9K impressions 🎯 3.6% average CTR 📊 Climbing to an average position of 16 — and still rising And here's the part I'm most excited about: I didn't do this the "hire an agency and wait 12 months" way. I built an AI agent named Hermes and put it to work. Here's what Hermes actually does 👇 🔑 Keyword research on autopilot — I gave Hermes live web access to Semrush and trained it to hunt down the highest-opportunity keywords for both the core pages and the blog. ✍️ Website + blog copywriting — Hermes writes copy that's built to rank and actually convert, not keyword-stuffed filler. 🕷️ Technical crawlability — I optimized the site so Google crawls and indexes it cleanly, no wasted crawl budget. 🤖 Not just SEO — AIO + GEO too. This is the piece most people are sleeping on. The site isn't only optimized for Google's crawler — it's optimized for the LLM engines like ChatGPT and Claude, so when people ask an AI for recommendations, ConvertFleet shows up there too. Search is splitting in two, and I wanted to win on both fronts. The takeaway for me: a well-trained AI agent + the right tools can compress months of SEO grind into weeks. 💬 If you've pulled off something similar — ranking a site or platform with the help of AI — drop your results in the comments. I want to see them. And I'm curious what you think about the AIO/GEO angle specifically. Is optimizing for LLM answers the next big shift, or is it still early? Let me know below. 👇 #SEO #AIO #GEO #AIAgents #GrowthMarketing #SearchConsole
0
0
1-30 of 1,131
powered by

skool.com/automation-tribe-free-1232
Learn to build smart automations with n8n, Make.com, and AI. Free tutorials, workflows, and a community that helps you automate everything.
Suggested communities
Powered by