Activity
Mon
Wed
Fri
Sun
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
What is this?
Less
More
Memberships
The AI in Lending Report
85 members • Free
7 contributions to The AI in Lending Report

Apr '25 •
The question they should ask....
Duolingo will replace contract workers with AI How Long Before the article is "Consumers will replace DuoLingo with AI"? Companies must think much longer term in their adoption of AI, and less what can it do for me today. As soon as they answer that question, the technology has already moved years ahead!!

Apr '25 •
Can AI Get Better and Cheaper Faster Than Expected?
When Brimma started doing document AI with OpenAI tech almost a year ago, the cost per document was close to $1. There is not much of an economic model to use something that expensive. Fortunately, a year later, the cost is a small fraction of that. There are already "laws" people have proposed on how fast AI capability will expand and cost will decrease (e.g. "Hyper Moore's Law") The question that occurs to me with this article is whether these "laws" are too conservative. That is, will AI get better and cheaper even faster? Why do I think that may be the case? In the article, there are two elements that will be key: First, DeepSeek is putting head-on pressure on all other models to deliver at a fraction of the cost. 97% cheaper is more than throwing down the gauntlet. Second, DeepSeek's tests were run on Huawei's chips...which is a throw-down to every using Nvidia or their own custom chips. I'm not betting against OpenAI, Gemini, or Nvidia, but this arms race is unbelievable!
1 like • Apr '25
The question that comes to my mind is.... Will US enterprises be willing to put their investment into DeepSeek even at a 97% cost reduction. It will put pressure on ChatGPT and others for sure, but I think DeepSeek has a high mountain to climb in terms of trust.
Apr '25 •
Teach AI to Work Like a Member of Your Team
Many companies see little impact from AI tools because generic models don’t align with how teams actually work. A contracts team struggled to use an off-the-shelf tool until the company mapped their workflow and fine-tuned the model. The result: more accurate outputs, less manual effort, and a 30% boost in throughput. The takeaway for leaders is that context is essential—real productivity gains come from aligning AI with specific team processes. Full Article
1 like • Apr '25
Great article, that approach will certainly save you time and help with adoption.
Apr '25 •
Microsoft's 1-bit AI LLM
Microsoft just dropped a 1.58-bit LLM—and no, that’s not a typo. BitNet b1.58 2B4T (yes, that’s the real name) is an open-source, ultra-lightweight large language model that’s trained on 4 trillion tokens and can actually run on a CPU—like, say, your MacBook’s M2 chip. It clocks in at 400MB of memory usage, spanks models like Meta’s LLaMa 3.2 and Google’s Gemma 3 in several benchmarks, and even decodes faster on a CPU. While that's impressive, 400MB of memory is still way more than any everyday device is going to want to allocate to one program...at least as far as my laptop, phone, and watch are concerned 😉 The catch? You have to use Microsoft’s custom bitnet.cpp framework to see those speed gains—don’t expect miracles if you're just tossing it into Hugging Face Transformers. So… what does this mean? Less power, less memory, local compute—and maybe, just maybe, a path to AI that doesn’t require a server farm or a second mortgage. Could 1-bit AI unlock a future of hyper-efficient, decentralized intelligence? Someone should probably ask that. Preferably before the GPUs run out. Link to Article
0 likes • Apr '25
How does a locally run desktop/mobile model continue to update? Does it self update?
Apr '25 •
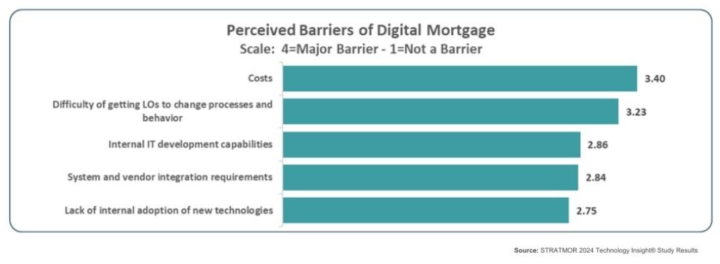
Stratmor's "Laying the Foundation for a Seamless Digital Mortgage Experience"
Can't help but feel this article is "deja vu all over again" (Yogi Berra). It seems point to LO's not wanting to adopt new tech as a concern, but every day lender's are adopting POSs that they know are not best-in-class but they adopt them because their LOs demand a platform they are already familiar with. https://www.stratmorgroup.com/laying-the-foundation-for-a-seamless-digital-mortgage-experience/
1 like • Apr '25
We have been hearing about "seamless digital mortgage" for the past 15+ years!!
1-7 of 7
Active 288d ago
Joined Mar 18, 2025
Powered by