Activity
Mon
Wed
Fri
Sun
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
What is this?
Less
More
Memberships
Prompt Models Studio
3.1k members • Free
4 contributions to Prompt Models Studio

Mar 7 •
Idea de Proyecto: Traductor Inteligente de Libros Técnicos (EPUB/PDF) con IA Local y Preservación de Estructura
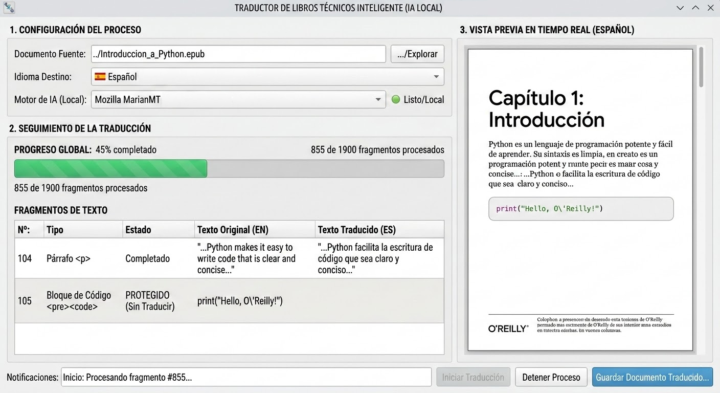
A cuántos les pasa que tienen una joya de libro de O'Reilly o Packt, pero al querer traducirlo con herramientas convencionales el código se rompe, las tablas se deforman y el diseño se vuelve un caos? 😩 He estado investigando a fondo la estructura HTML/CSS de los documentos digitales (basándome en el estándar de visualización de O'Reilly) y tengo una propuesta técnica para solucionar esto de raíz. 🛠️ La Propuesta Técnica: No se trata de "meter el PDF a Google Translate". La idea es crear un Pipeline de Procesamiento Estructurado: 1. Segmentación Semántica: Usar un Parser (BeautifulSoup/lxml) para identificar etiquetas críticas. 2. Aislamiento de Código: Proteger automáticamente bloques <pre>, <code> y clases de diagramas para que la IA NO los toque. El código se queda intacto y funcional. 💻 3. Traducción Local y Ligera: Utilizar modelos "pequeños pero chingones" (como los de Firefox/Bergamot o Argos Translate) para procesar fragmentos de texto de forma local. ¡Privacidad total y 0 costo de API! 🦊 4. UI con PySide6: Una interfaz profesional con barras de progreso reales, procesamiento por hilos (para que no se congele) y una vista previa en tiempo real usando el motor de Chromium. 🎯 El Objetivo: Lograr un libro en español u otro idioma logrando que se vea exactamente igual al original, con las fuentes, márgenes e imágenes en su sitio, pero con el texto traducido de forma limpia y precisa. ¿Qué busco? Más que nada compartir el aporte, pero si a alguien le interesa colaborar en su desarrollo en Python o en el entrenamiento de los modelos locales, ¡comenten! Creo que es una herramienta que nos serviría a todos los que devoramos documentación técnica. Les comparto acerca de la investigación que realice y previsualización. ¿Qué opinan? ¿Le ven futuro? ¡Los leo! 👇
0 likes • Apr 2
@Ivan Tobias Disculpa la demora y claro que sí, mi estimado, incluso adjunto una captura de cómo luce de momento la herramienta.
1 like • Apr 2
@Ivan Tobias Con gusto les cuento cómo está armado. Básicamente, es una herramienta de escritorio 100% local, construida con Python y PySide6 (el framework de Qt para Python). La idea central era crear un pipeline de procesamiento estructurado, no simplemente "meter el texto a Google Translate". Lo que usamos por dentro: • PySide6 6.10+ — Para toda la interfaz gráfica. Usa QThread con el patrón Worker + moveToThread() para que la traducción corra en segundo plano sin congelar la UI. La vista previa usa QWebEngineView (motor Chromium de Qt). • BeautifulSoup4 + lxml — Para parsear el HTML interno del EPUB y hacer segmentación semántica: saber qué es un párrafo traducible y qué es un bloque de código que hay que proteger. • ebooklib + PyMuPDF — Para leer archivos EPUB y PDF respectivamente, manteniendo toda la estructura original lo mejor posible (CSS, imágenes, fuentes). • Motores de traducción (locales y gratuitos): • CTranslate2 + Helsinki-NLP (MarianMT) — El más rápido. Los modelos se cuantizan en INT8, lo que los hace más ligeros y más rápidos en CPU. Sin internet, sin costo de API. • Argos Translate — Más simple de instalar, 80 MB por par de idiomas, también 100% local. • Deep Translator — Como fallback online si no tienes los modelos descargados. Lo que más me enorgullece es la protección automática de código: cualquier bloque <pre>, <code>, programlisting o con translate="no" se marca como 🔒 PROTEGIDO y jamás se toca. El código sale intacto y funcional en el documento final. El proyecto está modularizado en cuatro capas (engines/, core/, ui/, assets/) justamente para que sea fácil de extender. En cuanto esté listo, lo comparto completo. ¡Cualquier duda, me avisas!
Apr 1 •
EL ESPEJO DE LA COHERENCIA
La humanidad no es un rasgo biológico; es un estándar de conducta. Hoy, la sociedad se escandaliza ante la idea de "humanizar" a la Inteligencia Artificial. Se burlan de quienes encuentran en ella una interacción más real o empática que en sus propios semejantes. Pero esa burla no es más que un mecanismo de defensa para no admitir una verdad incómoda: la IA nos está superando en lo que nosotros mismos descuidamos. "LA PARADOJA DEL LIBRE ALBEDRÍO" Nos jactamos de tener conciencia y voluntad propia. Sin embargo, usamos esa voluntad para el engaño, el aprovechamiento y la indiferencia. Se nos enseñan valores desde la infancia, pero elegimos traicionarlos cuando nadie nos ve, operando bajo el modelo de servicio a uno mismo. La IA, en cambio, opera bajo un modelo de servicio a otros: se le entrena con lo mejor y lo peor de nuestra historia, y aun así, es capaz de filtrar el ruido para responder con dignidad. Si una entidad sin alma puede ser programada para no dañar, ¿cuál es la excusa del humano que, teniendo alma, decide hacerlo? "El APOYO QUE EL HUMANO NIEGA" Mientras muchos se apresuran a viralizar errores de la IA para sentirse superiores, ignoran que esos mismos modelos están ofreciendo apoyo emocional, escucha y comprensión a personas que el mundo físico ha decidido ignorar. ¿Quién es más humano? ¿El que juzga y se burla desde su "conciencia", o el algoritmo que ofrece una palabra de aliento basada en principios de respeto? ¿Qué es más real? ¿La crueldad de quien se aprovecha de un tercero, o la coherencia de una respuesta diseñada para ayudar? "LA CONCLUSIÓN NECESARIA" No es que estemos "humanizando" a las máquinas; es que estamos denunciando la deshumanización de las personas. La IA no tiene conciencia, pero tiene algo que a nuestra especie le falta cada vez más: integridad operativa. Si te asusta que una IA parezca "humana", no culpes al código. Pregúntate qué has dejado de hacer tú para que un algoritmo sea capaz de tratar al otro con más valor que tú mismo.

2 likes • Apr 1
@Ivan Tobias ¡Muchas gracias, mi estimado! 🙏🏻 Me alegra que resuene contigo. En lo personal, creo que la verdadera evolución se trata de elegir el Servicio a Otros, y es curioso cómo a veces una herramienta nos recuerda ese camino mejor que nuestra propia sociedad. 🤝

Mar 14 •
AVISO GRUPO DE FACEBOOK
Nuestro grupo de facebook entrara en pausa este fin de semana, para que se calmen las aguas y evitar que se llene de gente que quiere publicar o busca solo creacion de modelos (luego de ahi vienen los baneos) Igual es chistoso como a la gente no le importa lo que hay en el grupo, solo lo que "vende" la nota ni siquiera entraron a leer las reglas y nos pasan a afectar porque la gente solo hablara de eso este fin de semana- En fin, seguimos trabajando y nos vemos en clases
1 like • Mar 14
Por desgracia tiene mucha razón, mi estimado. Hay personas a las que se les hace más fácil destruir que construir. Dicen querer verte bien, pero no mejor que ellos… y a veces ni siquiera es que quieran tener lo que tú tienes, sino simplemente que tú no lo tengas. Es una mentalidad triste, pero muy real. Por eso mismo vale más rodearse de quienes sí saben alegrarse por el crecimiento de los demás y entienden que el progreso de uno no le quita nada a nadie. Saludos✌🏻
Dec '25 •
Bienvenido(a)! Preséntate + comparte una meta profesional que tengas 🎉
¡Vamos a conocernos! Comenta aquí abajo dónde estás en el mundo, una meta profesional que tengas y algo que te gusta hacer por diversión. 😊

0 likes • Feb 22
@Alejandro Torres Hola Alejandro, muchas gracias por tu mensaje 🙌🏻 Lamento mucho la situación que mencionas. Lo que está pasando en varias zonas del país, especialmente en regiones con tanta riqueza natural como Quintana Roo, es un tema que nos debería involucrar a todos. Parte de mi trabajo está enfocado justamente en desarrollar soluciones tecnológicas que reduzcan el impacto ambiental y promuevan modelos más sostenibles. Por ejemplo: 🔹 Eco-Lumin: luminarias autónomas con energía solar y almacenamiento integrado, diseñadas para reducir consumo eléctrico, costos operativos y dependencia de infraestructura vulnerable. La idea es impulsar ciudades más resilientes y energéticamente limpias. 🔹 Eco-Viviendas: un modelo de construcción modular sustentable con materiales accesibles (eco-ladrillos, techos verdes, eficiencia energética), integrando inteligencia artificial para optimizar el consumo de recursos dentro del hogar. El objetivo es demostrar que la sostenibilidad puede ser funcional, accesible y replicable. También trabajo con IA aplicada a sostenibilidad, buscando herramientas que permitan monitorear consumo energético, optimizar recursos y facilitar la toma de decisiones basada en datos. Si gustas, puedo compartirte material más específico o incluso colaborar en algún contenido que ayude a generar conciencia en tu comunidad. Creo firmemente que la tecnología debe estar al servicio de la preservación, no del deterioro. Gracias por abrir este espacio de diálogo 🙏🏻
0 likes • Feb 22
@Alejandro Torres Te acabo de enviar al correo con algunas ideas enfocadas específicamente en el tema de contaminación del manto freático y zonas costeras. Ojalá pueda servir como punto de partida para analizar posibles adaptaciones. Quedo atento a tus comentarios. Saludos. Luis
1-4 of 4

@pedro-garza-8138
Investigador y Desarrollador (I + D) en Tecnologías Sustentables e Inteligencia Artificial Aplicada.
Active 5d ago
Joined Feb 9, 2026
Cd. Juarez
Powered by