Activity
Mon
Wed
Fri
Sun
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
Jul
What is this?
Less
More
Owned by Des
Build full-time income from small YouTube audiences. I did it in under 4 weeks with The Electric Oracle. Teaching 40+ creators the same systems.
Turn your Skool community into $1K-$5K/month - even with just 0-50 members
Memberships
Skool Events Daily
437 members • Free
Empowered Investor Pathway
7 members • $5,000
YouTube Mastermind
39 members • $2,000/year
9 contributions to Digital Roadmap AI Incubator

Jun 14 •
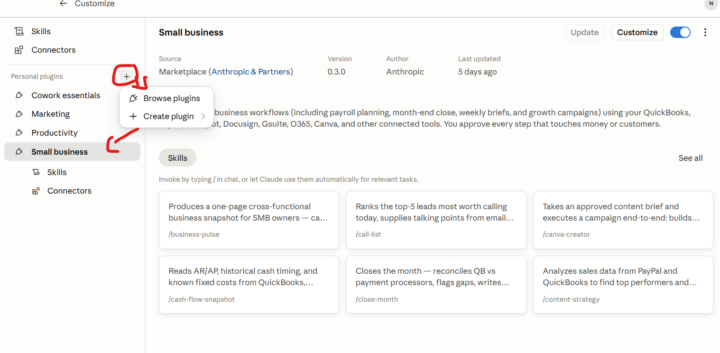
Claude For Small Business
Has anyone tried the Claude for small business plugin as yet? I plan to do a YouTube video on it soon and I can walk through it in our Tuesday session.👩🏾🦱 Claude for Small Business is a plugin you install directly inside the Claude desktop app through Claude Cowork. Think of it as a starter operating layer for your business. It comes pre-wired with connections to tools that many business owners already use. Accounting tools. Payment processors. CRM tools. Workspace tools. Document tools. Marketing tools. Communication tools and so on. The power is not just in the connectors. The power is in the skills and ready-to-run workflows that come with it.

🔥
2 likes • Jun 14
I haven't, but I'm gonna try it out now. Thanks for the heads up!
Apr 17 •
Claude Opus 4.7 Prompting
🚨 Claude Opus 4.7 is out. It's state-of-the-art on GDPval-AA (a third-party eval of real economically-valuable knowledge work), and it's the new default for the hardest tasks. Anthropic buried something important in their release notes: "Prompts written for earlier models can sometimes now produce unexpected results: where previous models interpreted instructions loosely or skipped parts entirely, Opus 4.7 takes the instructions literally. Users should re-tune their prompts and harnesses accordingly." Translation: prompts that worked on Opus 4.6, Sonnet 4.6, or any prior Claude model might quietly degrade on 4.7. Not because the model got worse. Because it got more literal. And this applies doubly to prompts written for other models. Your GPT-5.4 prompts with ::: markers and output contracts. Your Gemini prompts with data-at-top and negative constraints at the bottom. Those patterns were optimized for those models. On Opus 4.7, they produce friction. A few examples of what changes: If your prompt has two competing instructions (like "be concise" and "give a comprehensive analysis"), 4.6 smoothed that over. 4.7 picks one literally. "Challenge my assumptions" was useful on 4.6 and standard on Grok. 4.7 pushes back natively. Leaving the line in is clutter. "Be thorough" and "don't skip steps" were hedges against older models cutting corners. 4.7 is proactive by default. More clutter. Dense screenshots used to need downsampling. 4.7 handles images up to 2,576px on the long edge (3× the old resolution). I built a skill to fix all of this. 👾Join Monday's masterclass to learn how: https://links.convertwave.ai/widget/form/tElay6We4IZgzcXxsbuy?contact_id=U8htJWSeFEIBtYJWIYQf&fbclid=PAT01DUAROb7xleHRuA2FlbQIxMABzcnRjBmFwcF9pZA81NjcwNjczNDMzNTI0MjcAAacah6qLq0J1Zb1Ex_FkhWZ55nUHosab749SbfYtyGIlpUjYd3dsSFQou-COlg_aem_AJ5J2V65cSh3yLZ1KQttSw
🔥
1 like • Apr 17
@Nicole McCain AI would love to, but it looks like it's 11:30 pm for me at night. That's a little past my bedtime. 😂
🔥
0 likes • Apr 17
@Nicole McCain AI Cool, I'll likely watch the recording, then.
Mar 31 •
🔥Claude Cowork Marketing Dashboard
I created a YT video step by step to show you how to make this amazing claude cowork work Marketing Plan dashboard that integrates with your Google Calendar for tasks reminders. My editor is still working on the YT video but check out my Instagram video demo of it here and let me know if this is something you can use for your business:👇 https://www.instagram.com/reel/DWjht_UEfPT/?igsh=djR4ZTVrYmt0dTRw
🔥
2 likes • Mar 31
Hey @Nicole McCain AI thanks for sharing. This is incredibly nice of you. I'll take a look.
Feb 8 •
Wispr Flow is 🔥
Have any of you tried this app as yet? I am loving using Wispr flow to dictate instead of typing manually. Its saving me so much time and headache from trying to retype and correct mistakes when I'm typing. I can just talk just like this in natural tone, and it captures what I'm saying in any app that I'm using or any website. It's awesome. You guys can try it using the link below. ☺️👇 HERE
🔥
2 likes • Feb 9
My fave go to!
🔥
Dec '25 •
Hey, I'm Des
Hi everyone, Des here from the UK, and I really appreciate the warm welcome. Who I am: 51-year-old former marketing exec who monetised a small YouTube channel (The Electric Oracle) in under 4 weeks. Now I help 40+ professionals build sustainable revenue through content and community, without the toxic hustle. What excites me about AI: I'm deep in the Claude/ChatGPT ecosystem for content creation and client deliverables. The efficiency gains are staggering - I run my entire coaching business in 15-20 hours/week. My bottleneck: I'm scaling two communities simultaneously - The Content Revenue Lab (200+ members, free Skool focused on YouTube monetisation) and working on premium offerings. The challenge is balancing authentic engagement across platforms while maintaining the "anti-guru" positioning that resonates with my time-strapped audience. Looking forward to learning from the group and sharing what's working in the small channel monetisation space.
🔥
0 likes • Jan 16
@Mia Juliana Yes, I did that on my EV channel.
🔥
0 likes • Jan 16
@Mia Juliana The Content Revenue Lab 🙂
1-9 of 9

Active 34m ago
Joined Dec 2, 2025
Spalding