Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Memberships
AI Automation Society
415.9k members • Free
AI Automation Mastery
30k members • Free
Ai Automation Vault
15.1k members • Free
Agentic Academy
1.5k members • $37/month
9 contributions to AI Automation Society

10h •
Day 6 #AISChallenge (portfolio update from Schwab)
- What I scheduled: At 4:15 pm EST (right after market close), my script pulls my stock/ETF positions from two Schwab accounts via Schwab's API. Because Schwab's positions already include the field currentDayProfitLossPercentage, it is easy to return the top 5 daily % gainers and bottom 5 daily % losers. Via Perplexity's API, these 10 tickers are reported along with a brief summary per the Perplexity prompt: "In 2-3 concise sentences, explain the likely reason {symbol} stock is up/down about {abs(pct_change):.2f}% today. Focus on recent news, earnings, analyst actions, or sector trends if relevant. Be specific and brief." - What surprised me about how the agent ran without your input? This is a deterministic workflow: Fetch positions via Schwab API; Sort by currentDayProfitLossPercentage; call Perplexity with fixed prompt; dump to .md file. Attached is today's report. Except that the option positions confused Perplexity, it totally works. The ultimate version of this report will be really helpful to me. I don't spend all day every day looking at my portfolio. Like many "part time investors" that means this happens a lot a lot: among the daily trash heap of noise, you miss big news that moves your stocks. This report almost captures something I do manually on many (but not all) days: sort daily % moves, if only to cull out the news I might want to know. It's really exciting to believe that with APIs, Claude can build almost anything that I can imagine. Just like the website build assignment, Claude basically did everything on its own. We got stuck on Schwab's sandbox restriction, but Claude just told me what to do in python from the terminal. So, unlike all my previous coding experiences, I never felt actually stuck. As a *mediocre* coder sincerely, the difference between getting frustrated when stuck versus feeling like you won't really get stuck is such a big difference. That's the (artificial?) confidence that enables the feeling that "hmmmm ... I could maybe build anything I want!".
1 like • 9h
@Z Scott thanks! Yes, apparently Schwab's token expires every 7 days which Claude tells me "is unusually short". So I need to run the attached script manually each week.
5d •
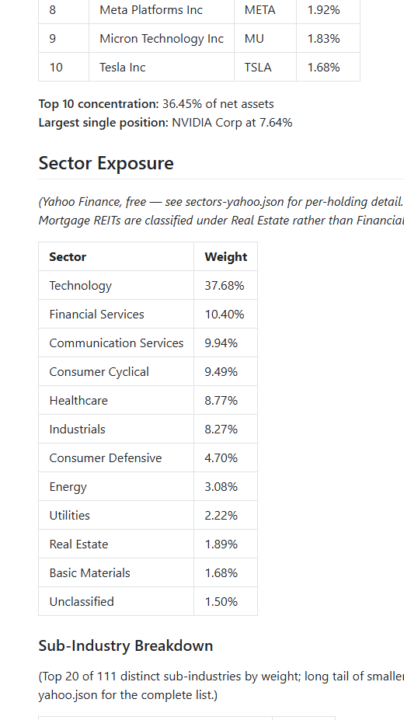
Day 3 #AISChallenge
What skill I built: holdings-report (one output shown). Given a fund's ticker (aka, symbol) it fetches the fund's holdings from its website and reports on the sector/industry exposure. One optimization I made: In the second version, I explicitly parsed out 2 subagents (holding-fetcher.md and holdings-analyzer.md) who invoke their respective "tools" (fetch-holdings.js and classify-sectors.js). Mostly I did this to wrap my head around the relationship between scripts, agents, tools and workflows. Also, I tested various APIs (i.e., called with various "tool" scripts) in order to variously classify holdings; e.g., is Amazon Internet Retail or Consumer Discretionary or a blend of several including Cloud Infrastructure ... I'm astonished at the power of Claude Code. It's disorienting to watch it work. I'm a slow, mediocre coder and coding is a frustrating experience for me. But with Claude, I guess you never have to get stuck? It's like managing a developer and watching him/her work. I love how i can interrupt with questions and then ask Claude to explain what it just did. At the end, I asked, "brilliant. Can you zoom back and explain how this project works in the context of Nate Herk's WAT (workflow, agents, tools) framework? ie., which are the agents, tools and workflows?" and it gave me a really great answer.
1 like • 3d
@Drew Pearson Thank you Drew! Your question gets to something that's harder than I expected, and I haven't yet solved it (for my long-term purposes). My long-term predisposition has always been to weight sectors/industries because I own stocks that defy single bucket classification. My first version simply retrieved sector/industry from Yahoo! Finance (https://github.com/ranaroussi/yfinance), which is free, but for each ticker only returns a single sector + industry. My second version delegated inference to Perplexity via its API (https://console.perplexity.ai/) which was surprisingly easy and good at inferring classification into GICS sub-industries (https://www.msci.com/indexes/index-resources/gics); i.e., using the GICS but rather trusting Perplexity to infer primary classification. For the third version, I paid for API access to https://www.dcsc.ai/ because their theory appeals to me: a company (ticker) returns a 2-column matrix for up to four levels (!) of sector granularity, where the columns are relevance and confidence; i.e., in theory, for each ticker, I'd get back a list of sectors easily sorted by relevance/confidence. On their site, their example is Apple (AAPL) returns sectors Computer Hardware (95%), Application Software (80%), Smartphones (80%), etc. I do not consider the math that summarizes a detailed "vector of assignments" to be a hurdle; e.g., on my first run of this version, I simply accepted the top 3 and standardized their scores to sum to 100%. But if the vector is basically accurate, I think there various fun way to process the sector vector. However, Claude discovered problems with their data. Amazing! I would have eventually noticed the problems, but Claude saw them immediately and even proposed workarounds. Amazing! But after a few hours of too many problems with the source, I quit this source (and asked for a refund. I recommended they ask Claude to check their data before going to market) ... although Claude was willing to keep going lol.
0 likes • 11h
@Drew Pearson Thank you! I agree the 10-K is probably the ultimate source, although it is messy and further--ironically--I'm not sure I'd always want to inherit Reportable Segments. For example, the largest industrial REIT Prologis (PLD) has 3 segments: RE rental operations, RE development, and Strategic capital. In that instance, I preferred DCSC which returned 4 vectors each with multiple classifications (e.g., logistics, automation, retail) because it seems near to investment factor exposure. However, as mentioned above, their source data has flaws that so far render it unusable to me. My second version above simply delegated sector + industry classification to Perplexity and--in my simple attempt--the prompt asked Perplexity to attempt classification into the GICS taxonomy (which I provided). As such, perplexity assigned each ticker into a single sector/industry/sub-industry ... but it appeared to do that very skillfully! I haven't gone back to refine the prompt to request a multi-sector split. Thank you!
1d •
Example of storm-research skill (applied to investment research)
I tested Nate's storm-research skill (he shared earlier today here https://www.skool.com/ai-automation-society/new-video-stanfords-method-turns-claude-into-a-phd-level-research-team?p=7000fecf) with an genuine use-case: I am trying to decide whether/how to add drone exposure to my portfolio where my leading candidates are two public companies (RCAT, ONDS). I suppose the general prompt could have been something like "what will be the size of the drone market in 5 years and which of the current players are likely to be leaders?" but I gave it a more detailed, specific prompt asking to feature the two candidate companies. Here's the output (you'll see in the video that Nate provided also the report template, which renders the neat green/red supported/challenged tags) https://bionicturtle.github.io/storm-research-reports/storm-reports/drone-industry-rcat-onds-briefing.html My initial, quick impressions: - Excellent product: I am so delighted by this council-of-experts approach, especially for purposes of investment decision-making; e.g., I'm current on all of SeekingAlpha's latest articles on RCAT, but this document is next-level skepticism - The built-in STORM expert panel is Practitioner, Academic, Skeptic, Economist, Historian. For my investment decision-making purpose, next I would REPLACE the Academic with CFA/Forensic Accountant/etc. But in the GENERAL, I think you'd consider swapping an expert(s) depending on the purpose (!). - Maybe because my prompt was detailed (not sure?), I used 75% of my session tokens. I had to interrupt and ask Claude to hurry up and finish. Claude is a revelation every day but now I'm becoming very aware of token usage ;)
0 likes • 1d
@Dionny Chejito Yes, good suggestion, thank you!
2d •
Day 5 #AISChallenge (website)
I'm excited to share https://ariasea.netlify.app/ because I feel like Claude killed it with the color scheme based on the Brand Guidelines I provided. Except for the logo that I iterated, this is Claude's first version of the site (!!). AriaSea is fictitious but based on https://altasea.org/, a local blue economy incubator who hosted an open house yesterday. So I thought I'd pretend to build them a new website. However, I did not use their site as inspiration (apparently Claude didn't need to be inspired ...) Hacks I used: frontend-design skill; Puppeteer; ChatGPT wrote the brand guide; MidJourney created the logo (with a prompt written by ChatGPT). I used netlify just because I have a legacy, starter plan at netlify, a platform that always gave me great experiences when i was deploying stuff there years ago.
0 likes • 2d
@Arjun Nalla Yes, of course you can copy (it's fictitious). I attached the brand guide (which ChatGPT wrote, as mentioned). Please advise if I can provide something else re "blueprint"? ... as mentioned, I prompted the frontend-design skill, so I'm not sure there's much to share ....
0 likes • 2d
@Richard Backstein Thank you!
3d •
Day 4 #AISChallenge
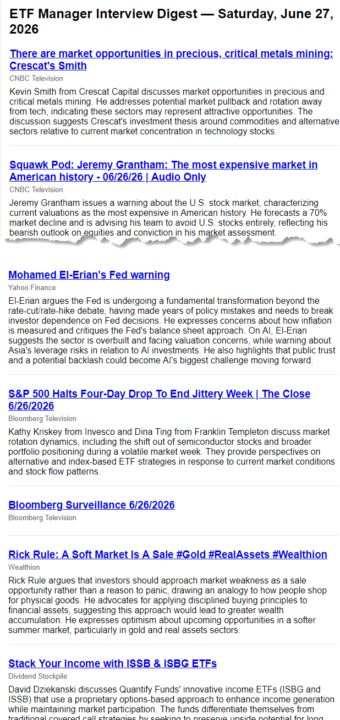
- What it does: sends me an email digest in the morning, with a link (+ summary) to new YouTube videos that meet my criteria - What I deployed (see screenshot): Workflow with two steps (aka, tasks). > The first task polls 12 YouTube channels for new videos once each morning (i.e., check-channels.ts is the single run at the bottom of the trigger screenshot with a yellow clock because it triggered at 5:00 AM) > The second task (the many process-video.ts runs because there's one run for each video) classifies each video: does the video feature an interview with a real fund manager, and is the video non-promotional? If both are true (i.e., isSubstantiveInterview=TRUE), then this task also summarizes the video (with claude-haiku-4-5). - One thing that broke: the lookback window is 25 hours, so a video from yesterday could possibly show up in today's run after it already showed up in yesterday's run. Apparently, by default trigger.dev only checks duplicates in the current run. Claude realized this "bug" by test triggering check-channel.ts twice in a row; and all the same videos unnecessarily called the Claude API again. So Claude Code switched to idempotencyKeys.create(video-${videoId}, { scope: "global" }) ... so the idempotency key is recognized across days.
0 likes • 2d
@Ahmad Khan Thank you. This was just a learning exercise for me, but I have two thoughts about time saving. First, I think when I get it configured right (with the sufficiently broad scope), I think it could save 3 to 5 hours per week. That's assuming I have the discipline to replace my normal browsing. Second, I think has the potential to add an entire set of capabilities to my awareness. I'm not sure what to call that. But currently without an agent doing smart browsing for me, I'm missing most of the content that's relevant to me. But a smart agent could be a super assistant for me. I think that's more powerful that saving me a few hours; it's giving me a superpower, or like adding a virtual assistant who is almost a junior analyst. Thanks again!
1 like • 2d
@Julius Waggoner Thank you, I will!
1-9 of 9
@david-harper-3654
Founder of bionicturtle.com (successful exit to PE). Investor in edtech and fintech.
Active 4h ago
Joined Sep 1, 2025
Powered by