Activity
Mon
Wed
Fri
Sun
Aug
Sep
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
What is this?
Less
More
Owned by Jason
Wake up with energy, keep pace with your kids, and respect the mirror again.
Memberships
Panda for Skool: The CRM +
413 members • Free
Clief Notes
40.1k members • Free
Remote Sales Secrets
581 members • Free
Lifestyle Founders
80 members • Free
Lifestyle Founders Group™
12.8k members • Free
Claude for Coaches
995 members • $47
Fulltime Freedom
6.3k members • Free
EverAds
625 members • Free
Decster - CSM for Skool
190 members • Free
7 contributions to Clief Notes

2h •
Getting the house in order...
Ok - some context - My introduction to Claude code was through an interactive tutorial that actually had me download all the software using the CLI, typing in the commands, and essentially at the end of it spit out a working website. That has grown and become the base for everything that I have now, and I'm wondering if and how to reorganize into the new folder structure. Obviously, everything is already in folders, I just don't know if they're in the right order or if they're organized as well as they should be. So my question to the group is, if you already have an existing infrastructure and it works, how do I go about reorganizing it for ICM efficiencies?


👑
⭐
3d •
🗺️ Afternoon Tea #9 from last week is in The Vault
Recording's up, and I packaged the whole thing so you can drop it straight into your second brain or hand it to your AI. 🍵 Here's what we got into this session: 🧠 Map your work, don't just store it. A second brain holds notes. A map holds your work plus the people and data around it — teams, processes, and the links between them. You can't improve what you can't see, and neither can your AI. 🔗 Every workflow is a node. One markdown file = one process. The references between them are the edges. That's the whole graph. 🟢 Build workflows, not outputs. Store the outputs inside the workflow. Then when Opus 4.8 or Fable ships, the right feeling is "cool, my system just got better" — not scrambling. 🔍 Google basically proved the method. Their new Open Knowledge Framework (dropped June 12) is markdown + files + front matter to document and query big datasets. One of the biggest players outside Anthropic is doing the markdown-and-files approach we've been practicing here. 👀 🏛️ Plus: mapping a real company's teams in Obsidian, the platform coming so you can own and license your workflows, and a sneak peek at my new paper — Human in the Compute Layer — built on Engelbart's 1962 work. 📎 What's attached (and what each file is for): 📝 session-notes.md — The opinionated version. All the ideas from the call, written so you can act on them. Start here if you want the short version. 📚 term-sheet.md — Plain-English definitions for every term: node, edge, semantic layer, OKF, ICM, "the data becomes the agent," and more. Perfect if you're new to the room. 📄 vault-page.md — The index for the whole package. 🗂️ Package.zip — Everything zipped, ready to add to your AI's memory (Claude, Hermes, OpenAI — whatever you run). 💬 Watch it, grab the files, and drop your questions below — the best ones seed the next Afternoon Tea. So much love. 🫶
0 likes • 11h
@Aaron Klein dope. I'll send you a DM. I have a user in my app that brought his 185 workouts from hevy. I uploaded them all for him so he gets to continue.
0 likes • 11h
@Aaron Klein nm. I can't DM until level 4. Give me a day or 2. 😂
👑
⭐
Apr 28 •
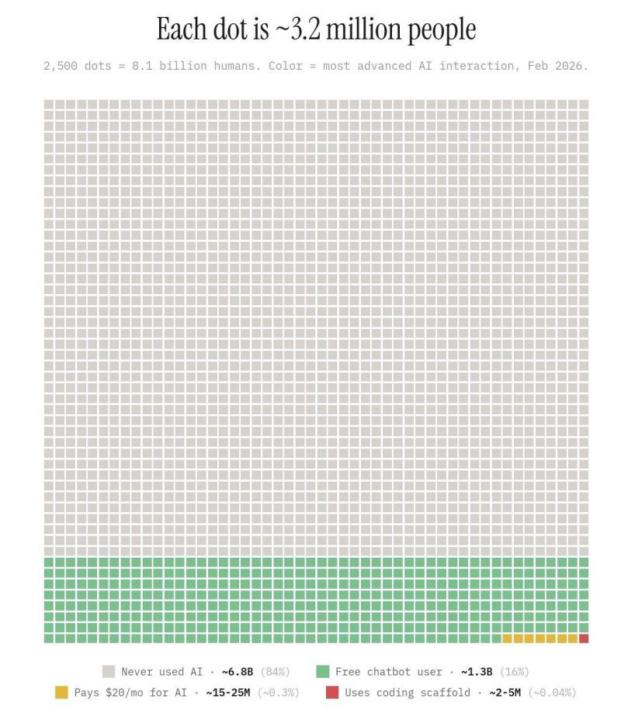
Each dot is 3.2 million people.
📊 You've probably seen this chart floating around LinkedIn and Twitter Each dot is 3.2 million people. ⬜ Grey is the 84% of humans who have never used AI 🟩 Green is the 16% who have used a free chatbot 🟨 Yellow is the 0.3% who pay for one 🟥 Red is the tiny sliver who use AI coding tools Most of the people sharing it have not actually said what it means. So here it is. 🔁 We live inside an algorithm. Mine shows me AI all day. Yours probably does too. Every reel, every post, every podcast clip, every ad. The feed makes it feel like the whole world has moved on without you and you are sprinting to keep up. Inside Clief Notes that feeling gets louder. You log in and see people building agents, shipping side projects, automating their inbox, talking about Claude Code and MCP servers like it is normal. In this room, it is. Step outside and almost nobody is doing any of it. 6.8 billion people have never opened a chatbot. Plenty of the ones who did opened it once, asked it something dumb, got a dumb answer, and decided the whole thing sucked. They are not coming back this year. Maybe not next year either. 🪖 When I was in the Marine Corps I never felt like I was doing anything special. I was surrounded by other Marines. Everyone around me could do what I could do. The standard was the standard. It was not until I left and stood next to people who had never served that I understood. The thing I thought was ordinary was rare. I just could not see it because I was inside it. That is what is happening to you in here. If you feel behind in this community, that is the right feeling to have. It means you are standing next to the people pushing the edge. Step outside this room and the thing you are calling behind is so far ahead of where most of the world is sitting that they cannot see you from where they are. And do not forget. The thing you built last week, the workflow you set up this morning, the conversation you just had with Claude. A version of you from two years ago would have paid good money to do any of it.
1 like • Apr 29
@Kevin Alldread lmao... every. damn. time.
1 like • Apr 29
@Gledi Kuburja just make sure to change your socks... ;-)
👑
⭐
Mar 9 •
Tell me what you want me to build you.
I had an idea. I want you all to comment A traditional workflow that you have right now. Like some sort of set of tasks that your industry does or what you're trying to do. I'm going to see how fast I can build some sort of prototype or solution that automates part of it in your industry or pain points and I'm just going to make a mass video that shows all of them for everyone who comments and this. Whatever I build if you want it DM me and I'll send you something. If you don't comment in this, I'm not building it But let's see what we can do. Everyone comment what you want me to build below or more importantly what you do and what your industry is
0 likes • Apr 22
@Gaganpaul Brar that's a cool idea!!
0 likes • Apr 22
@Brent Wright that's all? ;-) What a workflow! lol

Apr 17 •
Why are you here?
Jake talks about building systems that last a decade. That's a long time. What is the one thing you’re actually hoping to solve or scale with AI so you can focus on bigger things over the next 10 years? For me, it’s about mastering the technical logic so I’m not constantly chasing the next "hype" tool every six months. I want the systems to do the heavy lifting so I can reclaim my time.
1 like • Apr 19
@Alex Nartey honestly... The most basic part in it is what they use the most... The "weekly check in"... 😂
1 like • Apr 19
@Alex Nartey future features will just make it easier for the weekly check-ins so some data won't have to be self-reported it will just be visible.
1-7 of 7

Online now
Joined Apr 17, 2026
ENTJ
Owensboro, KY
Powered by