Activity
Mon
Wed
Fri
Sun
Oct
Nov
Dec
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
What is this?
Less
More
Memberships
University of Code
5.3k members • Free
Instagram Navigator
2.8k members • $20/m
9 contributions to University of Code

Jul 23 •
SLM Finetuning and Internals of LLM
Hi guys I have been working on finetuning small task specific models and would love to connect to people working closely with LLM .
0 likes • Jul 24
@Mark Sikaundi Healthcare , Mental Health and response gen. for classififcation , structured output and masked prompts
0 likes • Jul 24
@Likhit Tanishq yes Sure , what techniques are u using for finetuneing ?
Jun 12 •
Built a memory system for chatbots that mimics how humans remember and forget
Sharing a quick breakdown of something I recently built that dramatically improved long-session performance in LLM-based agents. The challenge => Most chatbots forget everything between sessions — or worse, overload memory with raw logs that aren’t meaningful. My solution => a structured memory system that’s adaptive, contextual, and forgets what it should. Here’s the architecture: 1. Memory Points - Each user message is turned into a memory point with: - A content summary - A dynamic importance score - A category (like “personal info” or “casual”) - A timestamp - Linked to a user ID 2. Memory Decay - Memories fade over time — but not equally. - Critical info (like names or settings) decays slowly - Small talk fades fast I use exponential decay with category-based rates. 3. Long-Term Summarization - When a memory fades below a threshold, the LLM generates a long-term summary (e.g., "User likes dark mode"). These are stored as part of the user’s evolving profile. 4. Contextual Retrieval & Conflict Handling - At inference time, the bot pulls in recent memory points + long-term memory. If there are conflicts, it resolves them based on score, recency, and category. Why it matters:It creates conversations that feel personalized and consistent, without storing everything. It’s lean, adaptive, and avoids token overload. If anyone else here is building AI agents or tools around personalization/memory — happy to trade notes or dive deeper!
1 like • Jun 26
@Toivo Mattila Mem0 is kind of memory context layer that wraps llms and provide contextual facts based on interaction. So if you want a LLM to remember stuff Mem0 is good . but for stuff where you want to manage how your vectors are being retrived followed my ordering . and finegrain control its better to implement from scratch .
1 like • Jun 26
@Toivo Mattila decay we're handled by workers on queues and crons and for rag it was dense search with sparse and decay for reranking memory .. so it kinda is sorted based on importance as well as timeline .. naturally it is in sync with ho LLMs process test as well so that is something that I kept in mind before building the hld Also I kinda don't know abt cursor .. is it something like v0? Personally I feel like LLM are great for boiler plate low value task .. as I have seen in most of the scenario if you know what you want then it's ok else hallucinations 🙄 Plus I don't know about langraph and langcchain as I was doing agents and tool calling kinda thing since gpt 3 time Hence don't have any idea abt these ..are these same ?
Apr 6 •
Idea Drop: GraphRAG for Production — Looking for Collaborators!
Hey everyone! I’ve been diving into the concept of GraphRAG lately and it seems like a super powerful way to improve RAG systems by integrating knowledge graphs for more structured and context-rich retrieval. I was wondering if anyone here in the PapaFam community is interested in exploring this idea together? Could be fun to experiment and maybe even build something cool for production-level use. Would love to connect with others curious about this too! Ps . It's a very important usecase .. as current rag does not maps the relationship between chunks Like true ER. This leads to a lot of loss in context Hit me up in dms if interested 🤞
1 like • Apr 6
@Arhan Ansari RAG is retrieval augmented generation.. think of a scenario where llm has to answer a query based on the knowledge it had acquired while training .. this is generic response .. but what Sonny showed in the ppt chat app .. the model now has examples to look before answering .. the idea of creating engineering solutions that can bring you the best sample for reference before answering is RAG .. rightnow there are alot of problems that rag fails to solve .. one being it does not understand relationships ... That's where graphrag comes in .. but it's still a concept .. no production level implementation exist .. although Microsoft has paper on it though
0 likes • Apr 6
@Likhit Tanishq that's great man .. it's agentic rag or a agent to query on retrieved docs ?
Mar 21 •
Journey 🚀 From Core ML to AI
Hey everyone! I’ve recently started diving deep into the world of AI, and I’m super pumped about the journey ahead! 🤖✨ AI is such a fascinating field, and I’d love to share what I’m learning with you all. If anyone has questions or is working on AI implementations and needs some help or insights, feel free to reach out! I'm here to collaborate, brainstorm, and dive into any challenges you’re facing. Let’s explore this amazing space together! 🌟💡 #AI #MachineLearning #SoftwareDev #AICommunity #Collaboration
Mar 6 •
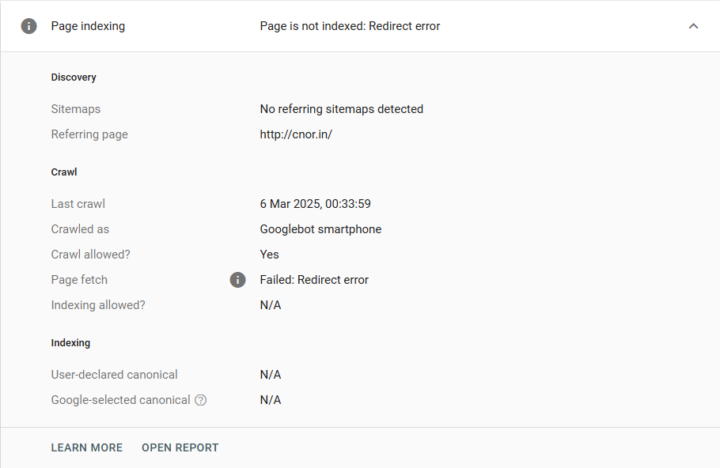
Need help with Clerk
Recently I built a project , but when indexing it it redirects the googlebot . I am using a production environment still and made homepage public still the bot is being redirected . Help plz anyone!!
0
0
1-9 of 9

@anmol-raj-2254
Seeking 2024 New Grad Opportunities | ML Developer | Founder @Purease | ML Intern @[email protected] | NLP | Generative Ai | Tensorflow & Azure Certified
Active 2d ago
Joined Jul 20, 2024
India
Powered by