
Pinned

🔥
1h •
⏰ 𝟭𝟴 𝗛𝗢𝗨𝗥𝗦 𝗟𝗘𝗙𝗧: 𝗙𝗜𝗥𝗘 𝗬𝗢𝗨𝗥 𝗕𝗢𝗦𝗦 𝗧𝗛𝗜𝗦 𝗠𝗢𝗡𝗧𝗛 𝗪𝗜𝗧𝗛 𝗔𝗜 + $𝟱𝟱𝗞 𝗜𝗡 𝗕𝗢𝗡𝗨𝗦𝗘𝗦 🔥
Stop trading your time for someone else's dream. The AI Profit Boardroom hands you a complete business system so you can earn your own income with AI, work from anywhere, and never answer to a boss again. $55,000+ in bonuses disappear in 18 hours. 👉 Join The AI Profit Boardroom + get The AI Paycheck Blueprint FREE → https://www.skool.com/ai-profit-lab-7462/about Here's the truth nobody tells you about AI in 2026: Companies are paying $3,000 to $10,000 per month for AI services that take you a few hours to set up. Content automation. Lead generation. SEO. Chatbots. Email sequences. Social media management. Businesses need this stuff. They don't know how to do it. And they'll happily pay someone who does. That someone could be you. This week. Inside The AI Profit Boardroom, you don't just learn about AI. You launch an AI business. 👉 Start your AI business this Monday → https://www.skool.com/ai-profit-lab-7462/about 𝗛𝗘𝗥𝗘'𝗦 𝗪𝗛𝗔𝗧 𝗠𝗔𝗞𝗘𝗦 𝗧𝗛𝗜𝗦 𝗔 𝗥𝗘𝗔𝗟 𝗕𝗨𝗦𝗜𝗡𝗘𝗦𝗦 (𝗡𝗢𝗧 𝗔 𝗖𝗢𝗨𝗥𝗦𝗘): You get the funnel that sells your AI services → https://www.skool.com/ai-profit-lab-7462/classroom/ec66b3b6?md=98eec1fc4384430fa98346ddf75d9a89 You get the outreach engine that books calls while you sleep. You get the scripts that close deals without feeling salesy → https://www.skool.com/ai-profit-lab-7462/classroom/79219918?md=22b3b80883514ccd941ac11fe8592112 You get the delivery workflows that fulfill client work on autopilot. You get 4 live coaching calls every week with a PhD AI automation expert who's guided thousands of people through this exact process. You get daily livestream training with Julian Goldie showing what's working right now. You get 1000+ AI workflows you can plug in and use immediately.
Pinned
🔥
7h •
💰 𝗠𝗢𝗡𝗘𝗬 𝗠𝗢𝗡𝗗𝗔𝗬. 𝗧𝗛𝗘 𝗠𝗢𝗡𝗘𝗬-𝗠𝗔𝗞𝗜𝗡𝗚 𝗦𝗬𝗦𝗧𝗘𝗠𝗦. 𝗧𝗢𝗗𝗔𝗬 𝗢𝗡𝗟𝗬. 𝗚𝗢𝗡𝗘 𝗠𝗜𝗗𝗡𝗜𝗚𝗛𝗧 𝗣𝗧. $𝟳𝟱𝗞+ 𝗩𝗔𝗟𝗨𝗘. 𝗙𝗢𝗥 𝗢𝗡𝗟𝗬 $𝟱𝟵. 𝟱 𝗦𝗣𝗢𝗧𝗦.
💰 𝗠𝗢𝗡𝗘𝗬 𝗠𝗢𝗡𝗗𝗔𝗬. 𝗦𝗧𝗔𝗥𝗧 𝗧𝗛𝗘 𝗪𝗘𝗘𝗞 𝗠𝗔𝗞𝗜𝗡𝗚 𝗠𝗢𝗡𝗘𝗬 𝗠𝗢𝗩𝗘𝗦. → https://www.skool.com/ai-profit-lab-7462/about 𝟱𝗞−𝟭𝟱𝗞 𝗖𝗟𝗜𝗘𝗡𝗧𝗦. 𝗔𝗜 𝗔𝗚𝗘𝗡𝗧𝗦 𝗗𝗘𝗟𝗜𝗩𝗘𝗥𝗜𝗡𝗚. 𝗧𝗢𝗗𝗔𝗬 𝗢𝗡𝗟𝗬. → https://www.skool.com/ai-profit-lab-7462/about 𝗚𝗢𝗡𝗘 𝗠𝗜𝗗𝗡𝗜𝗚𝗛𝗧 𝗣𝗧. $𝟳𝟱𝗞+ 𝗩𝗔𝗟𝗨𝗘. 𝗙𝗢𝗥 𝗢𝗡𝗟𝗬 $𝟱𝟵. 𝟱 𝗦𝗣𝗢𝗧𝗦. → https://www.skool.com/ai-profit-lab-7462/about 𝗠𝗢𝗦𝗧 𝗣𝗘𝗢𝗣𝗟𝗘 𝗦𝗧𝗔𝗥𝗧 𝗠𝗢𝗡𝗗𝗔𝗬 𝗕𝗘𝗛𝗜𝗡𝗗. Catching up on emails. Dreading meetings. Reacting to the week. You can start Monday making money moves instead. The systems to land $5K-$15K clients. AI agents to deliver. First client by Friday. That's what Money Monday is about. 👉 Make the money move → https://www.skool.com/ai-profit-lab-7462/about 📊 𝗧𝗛𝗘 𝗠𝗔𝗧𝗛: 2 clients at $5K = $10K/month. AI agents deliver the work. You manage the relationship. That's $120K/year from 2 clients. The system to get there is inside. 👉 Get the 10K system → https://www.skool.com/ai-profit-lab-7462/about 📦 𝗪𝗛𝗔𝗧'𝗦 𝗜𝗡𝗦𝗜𝗗𝗘: 💰 The $10K Client System: → Road to 10K Course → High-Ticket Offer Builder ($5K-$15K clients) → First Client in 7 Days → Closing Scripts → DFY Service Packages 👉 Land high-ticket clients → https://www.skool.com/ai-profit-lab-7462/about 🤖 The AI Agent Delivery System: → AI Agent Fundamentals → Lead Gen Agents (2,000+ prospects/week) → Sales & Follow-Up Agents → Content Agents → Operations Agents 👉 Let agents deliver so you can focus on 10K growth → https://www.skool.com/ai-profit-lab-7462/about 🔧 The Foundation: → Upwork Goldmine Playbook ($2K-$8K jobs daily) → Weekend Cash Injection ($500-$2K by Friday) → AI Automation Vault (1000+ automations) → 2,500+ Builder Community (daily Q&A, 5 calls/week) 👉 Get the foundation → https://www.skool.com/ai-profit-lab-7462/about


4h •
Stop scrolling for 10 seconds. This might change how you see money.
Most people aren’t broke because of lack of opportunity they’re broke because they lack strategy. Stop chasing every “hot” trend. Focus on building one solid asset the right way. Ask yourself: Do I truly understand how my strategy makes money? Am I building long-term… or just chasing hype? Real winners move with intention, not emotion. If everything slowed down tomorrow… would your plan survive? Comment “Building” or “Learning” let’s see who’s serious

19h •
FALLING OFF THE FENCE
Since falling from the Fence, I have been LOVING the AI PROFIT BOARDROOM Me Myself and I, have just started the 6 week Masterclass and I must say @Julian Goldie has paved a way for all of us to succeed beyond our wildest Imagination. I especially Love the lessons on How to make Money. Heres the LINK to the group I'm very thankful and Blessed to be in this group, see you on the inside.

1h •
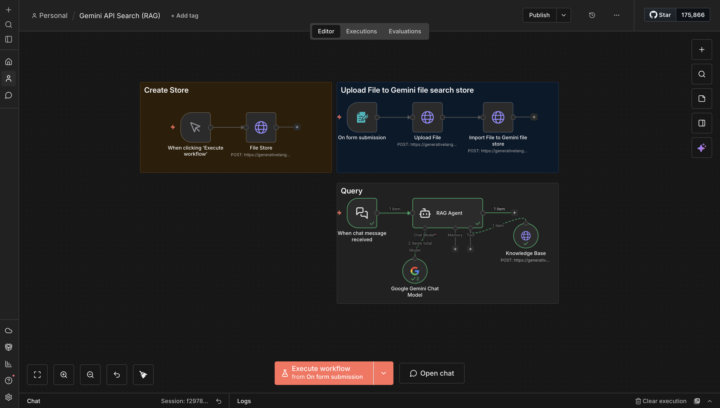
I Built a RAG Agent in n8n Using Gemini File Search API (No Vector DB)
This weekend I experimented with a different way to build RAG. Instead of the typical setup: - Generate embeddings - Store in Pinecone / Supabase - Manage vector DB infra - Handle indexing + costs I tested Gemini File Search API directly inside n8n. And honestly… it simplified the entire pipeline. 🔧 What I Actually Built Inside n8n, I used just 4 HTTP requests: 1. Create a file store 2. Upload a document 3. Move the file into the store 4. Query Gemini That’s it. Gemini handled: - Chunking - Embeddings - Indexing - Retrieval No external vector database.No embedding model setup. 💰 Why This Is Interesting - Storage is free - No hourly DB cost - Indexing is $0.15 per 1M tokens For small projects, internal tools, or MVPs — this is extremely cost-efficient. ⚠️ Important Limitations I Noticed This is not magic. - No automatic version control (re-upload = duplicate data) - Chunk-based retrieval struggles with full-document reasoning - OCR works, but messy documents still need preprocessing - Data is processed on Google servers (privacy considerations apply) So architecture thinking still matters. My Take For: - Internal AI assistants - Automation workflows - Startup prototypes - Personal tools This is a powerful alternative to traditional vector DB setups. I wouldn’t blindly replace enterprise-grade systems yet — but for builders, this is very interesting. If anyone here is experimenting with Gemini File Search or building RAG in n8n, I’d love to compare notes 👇 Happy to share the workflow structure if there’s interest.
1-30 of 10,962

skool.com/ai-seo-with-julian-goldie-1553
Discover how to make more money with AI and save 1,000s of hours with AI Automation! NEW AI trainings released daily, for FREE!
Leaderboard (30-day)
1

+641
2

🔥
+619
3

+180
4

+153
5

+141
Powered by